[파이토치 딥러닝 프로젝트] 심층 순환 신경망(RNN)
‣ 해당 블로그는 ⌜실전! 파이토치 딥러닝 프로젝트⌟를 공부하며, 배운것들을 토대로 정리되었음을 알려드립니다.
순환 신경망(RNN, recurrent neural network)
X(혹은 y)가 단일의 독립 데이터 포인트뿐 아니라 데이터포인트의 시간 순서 [X1,X2..Xt] 또는 [y1,y2,,yt]인 순서를 모델링할 수 있는 종류의 신경망
X2(시간 단계 2에서 데이터 포인트)는 X1에 종속되고, X3는 X2와 X1에 종속되는 과정
→ 이러한 네트워크가 순환 신경망(RNN)
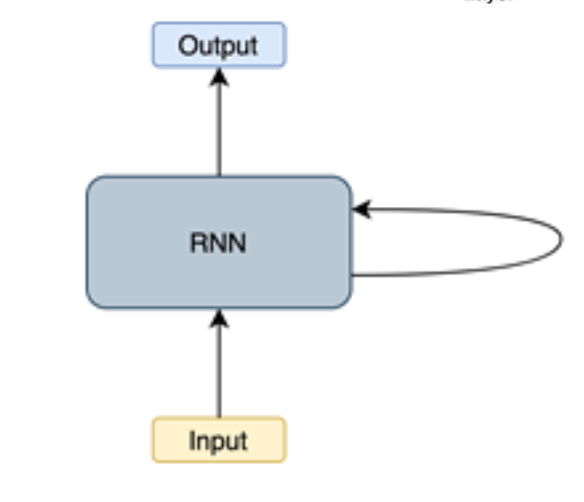
이와 같이 네트워크에서 주기를 생성하는 모델에 추가적인 가중치를 포함해 데이터의 시간적 측면을 모델링 할 수 있음.
신경망
데이터 셋의입력(X)과 출력(Y) 사이의 복잡한 패턴을 학습하는 데 사용되는 강력한 머신러닝 도구
주기(Cycle)
주기의 개념은 순환(Recurrence)이라는 용어를 설명하고, 이 순환은 RNN에서 기억(Memory)의 개념을 수립하는 데 도움이 됨.
RNN에서는 숨겨진 내부 상태를 유지하면서 시간 단계 t에서 중간 출력을 시간 단계 T+1의 입력으로 쉽게 사용할 수 있다.
RNN 다양한 종류
- LSTM(long short-term memory)
- GRU(게이트 순환 유닛, Gated recurrent unit)
해당 페이지에서는 위와 같은 종류를 중점으로 다뤄봄
순환 신경망 유형
'지도 머신러닝' 모델은 대체로 일대일 관계를 모델링하지만, RNN은 다음유형의 입출력 관계를 모델링할 수 있다.
- 다대다(동시적인)
EX) 명명된 개체 인식: 문장/텍스트가 주어지면, 이름, 조직, 위치 등과 같이 명명된 개체 범주로 단어를 태깅
- 다대다(인코더-디코더)
EX) 기계 번역(영어→한글): 자연어로 된 문장/텍스트를 가져와 통합된 고정 크기의 표현으로 인코딩하고, 해당표현을 디코딩해 다른
언어로 된 같은 뜻의 문장/텍스트를 생성
- 다대일
EX) 감정 분석: 문장이나 텍스트 일부가 주어졌을 때, 긍정적인 표현인지, 부정적인 표현인지, 중립적인 표현인지 등을 분류
- 일대다
EX) 이미지 캡션 생성: 이미지가 주어지면, 이를 설명하는 문장/텍스트 일부를 생성
- 일대일 → 그다지 유용하지는 않음
EX) 이미지분류(이미지 픽셀을 순차적으로 처리함으로써)
일반적인 NN 모델과 RNN 모델 유형 비교

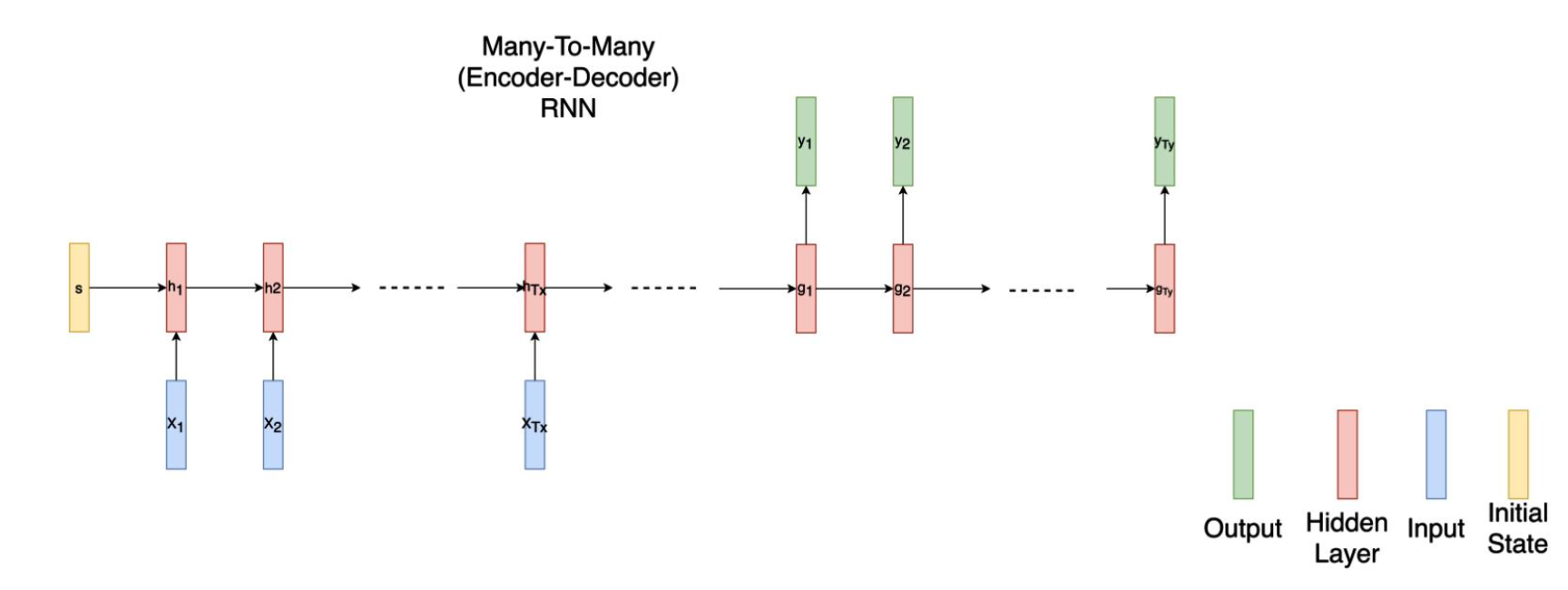
위 구조를 보게되면, 순환 신경망에는 일반적인 신경망에는 없는 "순환 연결"이 있다. 이 "순환 연결"은 이전 다이어그램에서 시간 차원따라 펼친다.
이번 다이어그램을 보게 되면 RNN 구조를 시간으로 펼친(time-unfolded)모습과 펼치치 않은(time-folded)모습을 보여주고 있다.
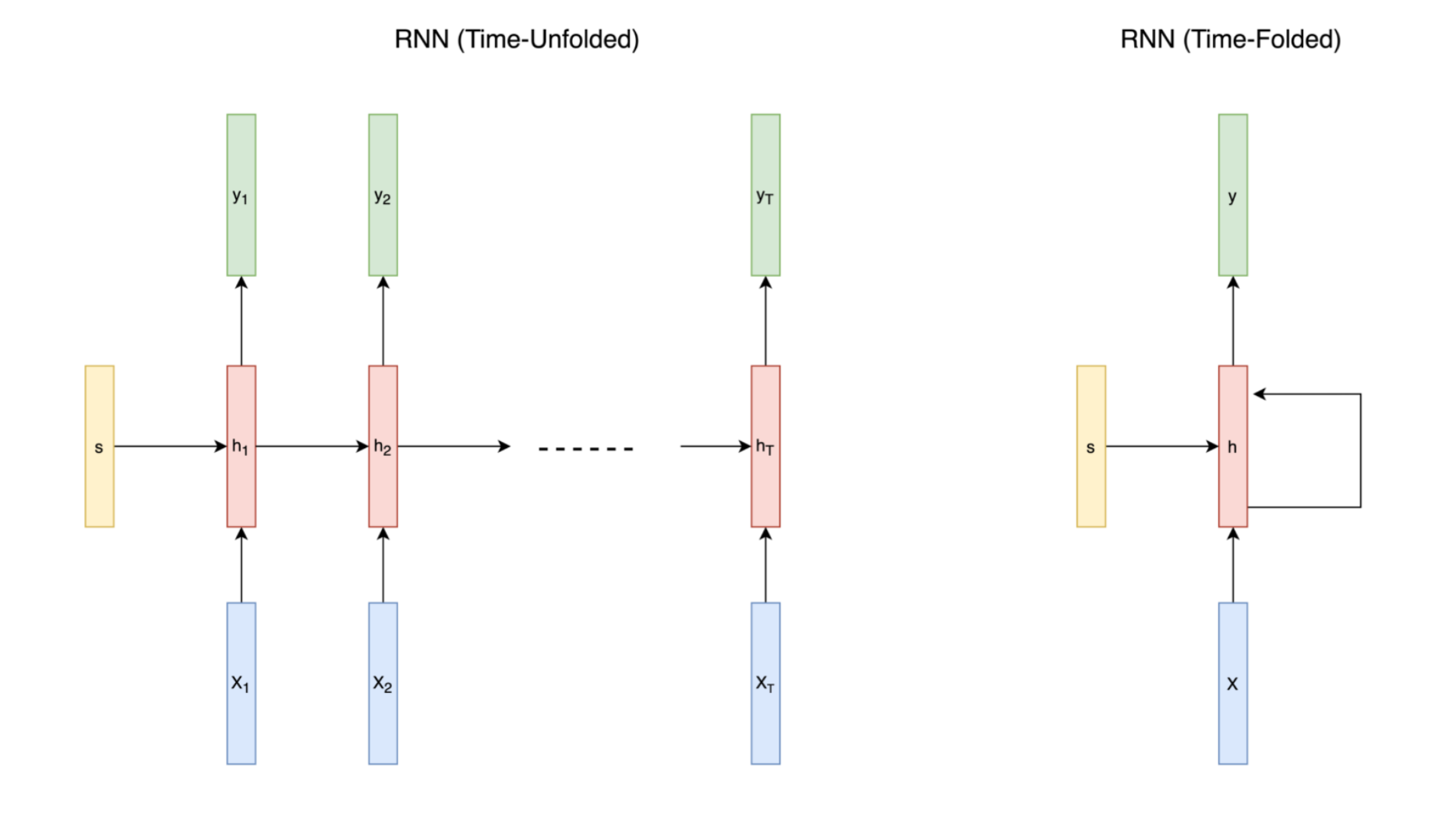
이어서 RNN 아키텍처를 설명할 떄는 시간으로 펼친 버전을 사용하여 전개하겠다. 앞의 다이어그램에서 RNN 게층은 신경망의 은닉 계층으로 빨간색으로 표시했다. 이 네트워크에서는 은닉 계층이 하나만 있지만, 이 은닉 게층을 시간 차원을 따라펼치면 이 네트워크에는 실제로 T개의 은닉 계층이 있다는 것을 알 수 있다. (T = 순차 데이터에서의 전제 시간 단계의 수)
RNN의 막강한 특징 중 하나는 다양한 길이(T)의 순차 데이터를 다룰 수 있다는 것이다. 길이가 서로 달라도 처리할 수 있는 방법은 길이가 짧은 데이터에 패딩을 추가하고 길이가 긴 데이터는 잘라내는 것이다.
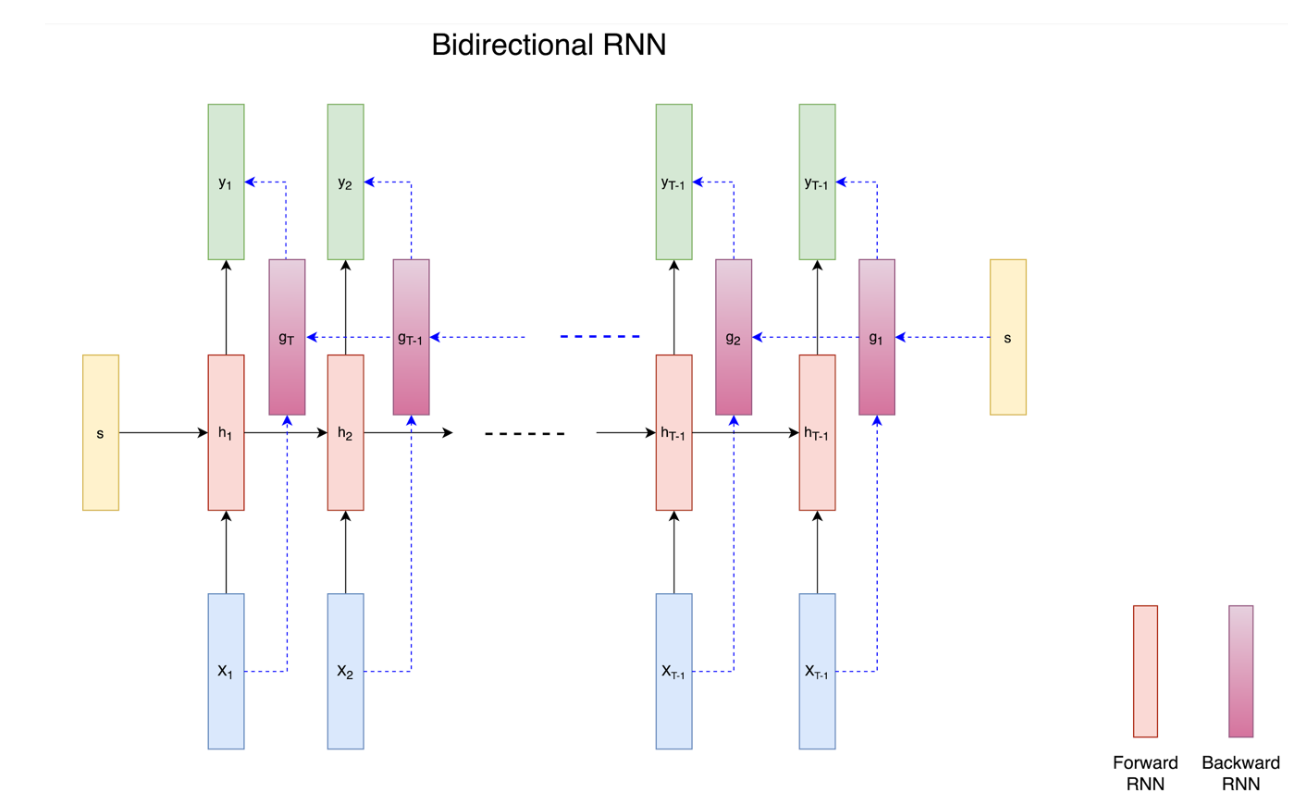
양방향 RNN
RNN이 순차 데이터에서 성능이 좋지만, 언어 번역 같은 일부 순서가 중요한 작업은 과거와 미래 정보를 모두 살펴봄으로써 더 효율적으로 수행할 수 있었다.
이와 같은 예시가 있다고 할 때 , 영어 'I see you' -> 프랑스어 'Je te vois' / 'te' = 'you' , 'voi = 'see'
영어를 프랑스어로 올바르게 번역을 하기 위해서는 프랑스어 두 번째와 세 번째 단어를 쓰기 전에 영어 세 단어 모두를 알아야한다.
양방양 RNN은 내부적으로작동하는 2개의 RNN이 있다는 것을 제외한다면, 일반적인 RNN과 매우 비슷하다. 2개의 RNN은 다음 다이어그램처럼 하나는 처음부터 끝가지 순서대로 실행되고, 다른 하나는 끝에서 처음으로 가는 순서대로 실행된다.
LSTM
RNN은 순차 데이터를 다룰 수 있고, 정보를 기억할 수 있지만, 경사가 폭발하거나 소실되는 문제(Long term dependency)를 안고 있다. 이 문제는 순환 신경망을 시간 축에 따라 펼치면 네트워크가 극단적으로 깊어지기 때문에 일어나는 현상이다. 추가적으로 이 문제에 대해서는 나중에 LSTM에 관해 따로 정리하겠다.
LSTM은 위와 같은 문제를 해결하기 위해서 RNN 셀이 더 정교한 메모리 셀인 LSTM(장단기 메모리) 셀로 교체한것. RNN 셀에는 일반적으로 시그모이드(SIgmoid)나 tanh 활성화 함수가 사용된다. 이 두 활성함수는 다음 다이어그램처럼 현재 시간 단계의 입력과 이전 시간 단계의 은닉 상태를 결합할 때 적용된다.
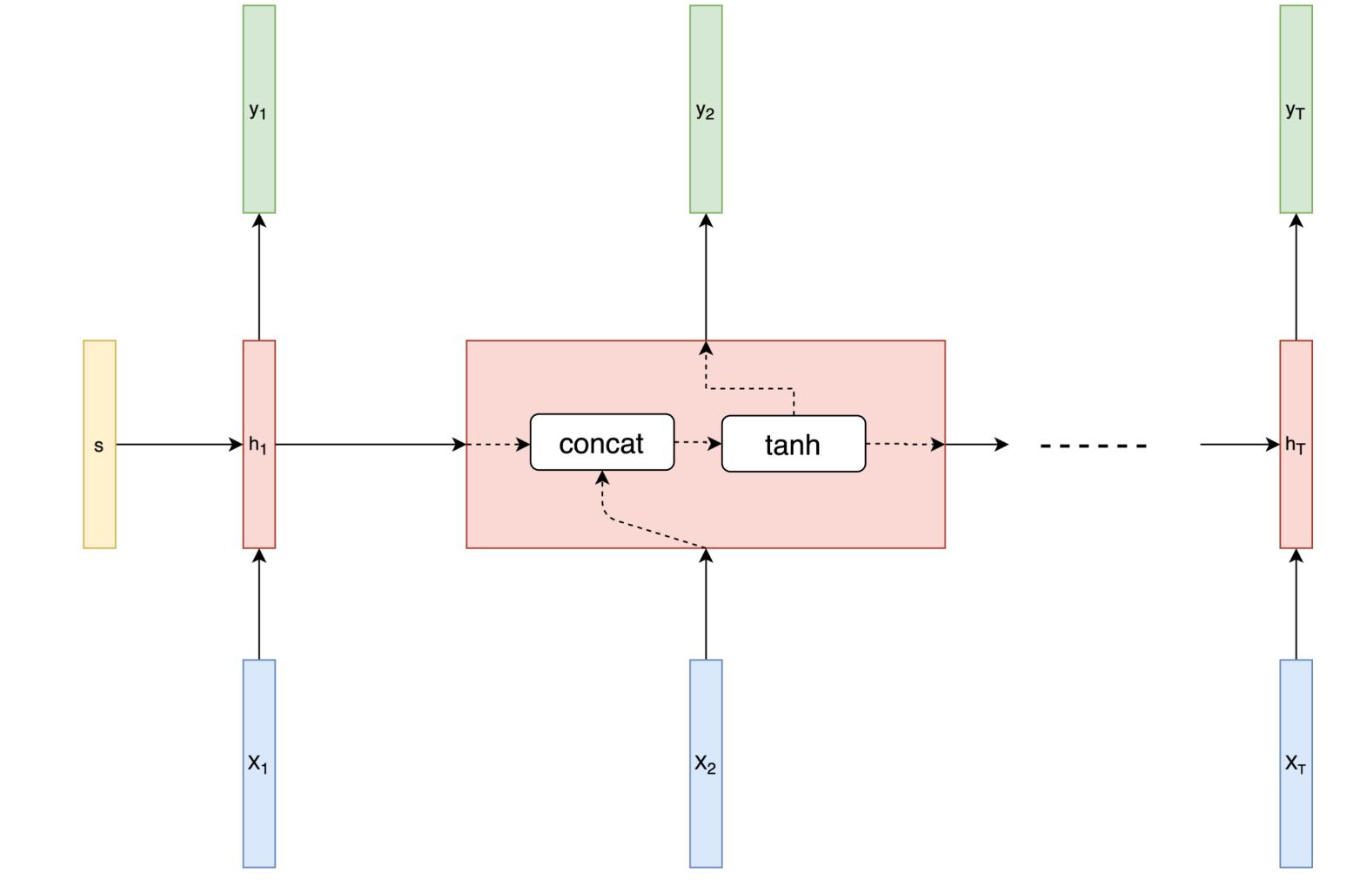
시간 축을 따라 펼쳐진 RNN 셀에서 경사 항을 곱하기 때문에, 경삿 값은 '역전파'되는 동안 이 RNN 셀에서 지속적으로 소실하거나 계속 증가한다. 따라서 RNN이 짧은 길이에서 순차적 정보를 기억할 수 있어도 길이가 길어지면 '곱셈'이 많아져 기억하기 힘들어진다. 'LSTM'은 게이트로 입력과 출력을 제어함으로써 이 이슈를 해결한다.
LSTM 계층은 시간에 따라 여러 셀로 구성되는데, 정보는 하나의 셀에서 다른셀로 셀 상태의 형태로 전달된다. 이 셀 상태는 게이트의 메커니즘을 통해 곱셈과 덧셈을 사용해 제어되거나 가공된다. 이 게이트는 다음 다이어그램에서 보듯, 이전 셀에서 오는 정보를 보존하거나 잊어버리면서 다음 셀로 흐르는 정보를 제어할 수 있다.
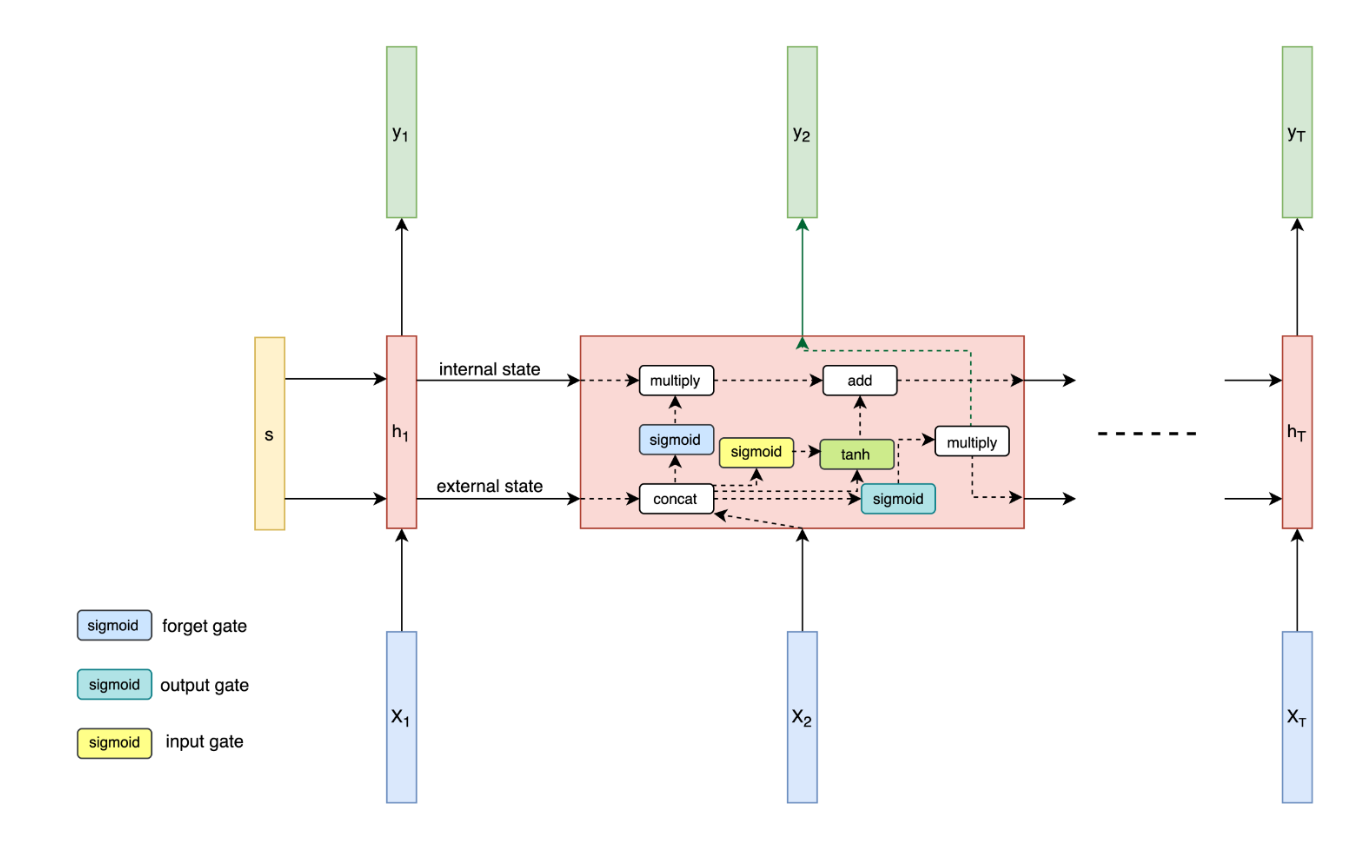
이러한 형태는 매우 긴 순차 데이터를 효율적으로 다룰 수 있다는 점에서 순환 신경망에 큰 혁신으로 다가왔다.
적층 LSTM
단일계층의LSTM 네트워크에서도 경사가 소실되거나폭발하는 문제를 극복하는 것 같지만, LSTM 계층을 여러 개 쌓으면 음성 인식처럼 다양한 순차 처리 작업에서 상당히 복잡한 패턴을 학습하는 데 더 많은 도움이 된다. 이러한 모델을 '적층 LSTM(Stacked LSTM)'

LSTM 셀은 본래 LSTM 계층을 시간 차원으로 쌓은 것이다. 공간 차원에서 그런 계층을 몇 개 쌓으면 공간상에 필요한 추가적인 깊이를 제공하게 된다.
☑︎ 단점
- 길이와 순현 연결이 늘어남에 따라 훈련 속도 매우 느림
- LSTM 계층이추가되면서 모든 훈련 이터레이션에서 시간 차원으로 펼쳐주어야함
- 여러 겹 쌓인 순환망 모델을 훈련시키는 것은 보편적으로 병렬 수행 불가
GRU
GRU(Gated Recurrent Unit)는 순차 데이터를 처리하는 데 사용되며, LSTM(Long-Term Memory) 네트워크를 개선하기 위한 모델이다.
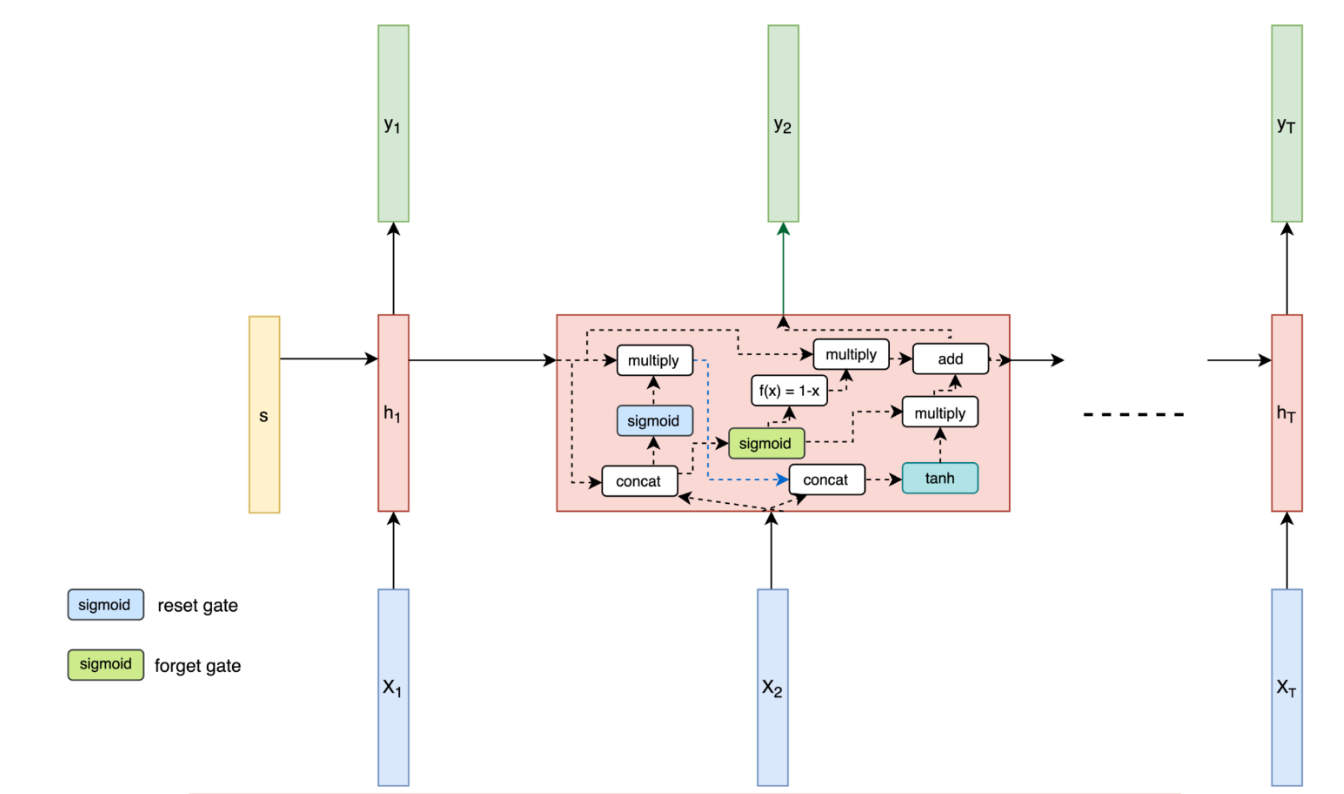
다이어그램을 보게되면 GRU는 '라셋 게이트(입력 게이트와 망각 게이트의 조합)'와 '업데이트 게이트'를 가지고 있다. 첫번째의 리셋 게이트를 이용하여 현재 상태에서 얼마나 이전 상태의 정보를 유지할 것인지 결정하고, 두번째 업데이트 게이트에서 이전 상태 정보와 새로운 정보를 결합하는 것 사이의 균형을 결정한다. GRU의 가장 큰 변화는 셀 상태를 두지 않고, RNN과 마찬가지로 하나의 출력만 한다는 것
이러한 구조는 LSTM보다 계산적으로 더 효율적이며, 학습 속도 또한 더 빠른 성능을 보여주고 있다.
RNN을 이용한 감성분석 : Pytouch
해당 실습은 IMDb 감성 분석 데이터 셋을 사용하고, Pytouch를 사용하여 RNN 모델을 훈련을 진행했다.
텍스트 조각(단어 시퀀스)을 입력받아 1(긍정적인 감정) 또는 0(부정적인 감정)을 출력하고, 순차데이터에 대해 이진 분류 작업을 위해 "단반향 단층 RNN"을 사용한다.
import os
import time
import numpy as np
from tqdm import tqdm
from string import punctuation
from collections import Counter
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(123)
IMDb 데이터셋은 영화 리뷰 텍스트와 그에 해당하는 감성 레이블(긍정 또는 부정) 으로 구성된다.
# read sentiments and reviews data from the text files
review_list = []
label_list = []
for label in ['pos', 'neg']:
for fname in tqdm(os.listdir(f'./aclImdb/train/{label}/')):
if 'txt' not in fname:
continue
with open(os.path.join(f'./aclImdb/train/{label}/', fname), encoding="utf8") as f:
review_list += [f.read()]
label_list += [label]
print ('Number of reviews :', len(review_list))
100%|██████████| 12500/12500 [00:00<00:00, 13570.44it/s]
100%|██████████| 12500/12500 [00:00<00:00, 14500.84it/s]Number of reviews : 25000
전체 25,000개의 영화 리뷰가 있고, 이 중 12,500개는 긍정적인 리뷰이며 나머지 12,500개는 부정적인 리뷰이다.
# pre-processing review text
review_list = [review.lower() for review in review_list]
# 구두점 모두 제거
review_list = [''.join([letter for letter in review if letter not in punctuation]) for review in tqdm(review_list)]
# accumulate all review texts together
reviews_blob = ' '.join(review_list)
# generate list of all words of all reviews
review_words = reviews_blob.split()
# get the word counts
count_words = Counter(review_words)
# sort words as per counts (decreasing order)
total_review_words = len(review_words)
sorted_review_words = count_words.most_common(total_review_words)
print(sorted_review_words[:10])
100%|██████████| 25000/25000 [00:01<00:00, 13231.57it/s]
[('the', 334691), ('and', 162228), ('a', 161940), ('of', 145326), ('to', 135042), ('is', 106855), ('in', 93028), ('it', 77099), ('i', 75719), ('this', 75190)]
먼저 전체 텍스트 말뭉치(corpus)를 소문자 처리한 다음,리뷰 텍스트에서 구두점을 모두 제거했다. 이후 다음 전체 리뷰에 나오는 단어를 모두 모아 단어 등장 횟수를 계산하고 가장 많이 사용되는 단어를 확인하기위해 등장 횟수를 기준으로 내림차순 정렬. 결과를 보게 되면 가장 많이 나오는 단어는 명사가아닌 한정사, 대명사 같은 것들이다.
보통 이러한 명사가 아닌 단어 '불용어'는 많은 의미를 전달하지 않기 때문에 말뭉치(corpus)에서 보편적으로 제거된다.
# create word to integer (token) dictionary in order to encode text as numbers
vocab_to_token = {word:idx+1 for idx, (word, count) in enumerate(sorted_review_words)}
print(list(vocab_to_token.items())[:10])
[('the', 1), ('and', 2), ('a', 3), ('of', 4), ('to', 5), ('is', 6), ('in', 7), ('it', 8), ('i', 9), ('this', 10)]
개별 단어를 숫자로 인코딩해주었고, 인코딩을 하기위해서 이전의 sorted_review_words의 빈도수를 사용하지 않고, word를 key로 사용하며, value로서 고유의 숫자를 부여해주었다.
이전에 내림차순으로 정렬을 해놓았기 때문에 가장많이 등장하는 단어를 1로부여하며 숫자를 할당해주었다.
reviews_tokenized = []
for review in review_list:
word_to_token = [vocab_to_token[word] for word in review.split()]
reviews_tokenized.append(word_to_token)
print(review_list[0])
print()
print (reviews_tokenized[0])
for a movie that gets no respect there sure are a lot of memorable quotes listed for this gem imagine a movie where joe piscopo is actually funny maureen stapleton is a scene stealer the moroni character is an absolute scream watch for alan the skipper hale jr as a police sgt
[15, 3, 17, 11, 201, 56, 1165, 47, 242, 23, 3, 168, 4, 891, 4325, 3513, 15, 10, 1514, 822, 3, 17, 112, 884, 14623, 6, 155, 161, 7307, 15816, 6, 3, 134, 20049, 1, 32064, 108, 6, 33, 1492, 1943, 103, 15, 1550, 1, 18993, 9055, 1809, 14, 3, 549, 6906]
이전에 단어에 정수를 매핑한 것을 사용하여, 본래의 리뷰 리스트들을 숫자 리스트로 변환해주었다.
# encode sentiments as 0 or 1
encoded_label_list = [1 if label =='pos' else 0 for label in label_list]
reviews_len = [len(review) for review in reviews_tokenized]
reviews_tokenized = [reviews_tokenized[i] for i, l in enumerate(reviews_len) if l>0 ]
encoded_label_list = np.array([encoded_label_list[i] for i, l in enumerate(reviews_len) if l> 0 ], dtype='float32')
감성 분류값인 긍정과 부정을 각각 숫자 1과 0으로 인코딩 해주었다.
def pad_sequence(reviews_tokenized, sequence_length):
''' 0으로 패딩되거나 sequence_length에 맞춰 잘린, 토큰화된 리뷰 시퀀스를 반환
'''
padded_reviews = np.zeros((len(reviews_tokenized), sequence_length), dtype = int)
for idx, review in enumerate(reviews_tokenized):
review_len = len(review)
if review_len <= sequence_length:
zeroes = list(np.zeros(sequence_length-review_len))
new_sequence = zeroes+review
elif review_len > sequence_length:
new_sequence = review[0:sequence_length]
padded_reviews[idx,:] = np.array(new_sequence)
return padded_reviews
sequence_length = 512
padded_reviews = pad_sequence(reviews_tokenized=reviews_tokenized, sequence_length=sequence_length)
plt.hist(reviews_len);

마지막으로 전처리 고정으로 다양한 길이의리뷰를 정규화하여 모두 같은 길이를 갖게 만들어주었다.
리뷰는 대체로 500 단어보다 짧아서 모델에 사용할 시퀀스 길이로 521(2의배수)를 선택하고 정확하게 512 단어 길이가 아닌 시퀀스를 그에 맞춰 수정해주었다.
train_val_split = 0.75
train_X = padded_reviews[:int(train_val_split*len(padded_reviews))]
train_y = encoded_label_list[:int(train_val_split*len(padded_reviews))]
validation_X = padded_reviews[int(train_val_split*len(padded_reviews)):]
validation_y = encoded_label_list[int(train_val_split*len(padded_reviews)):]
## If while training, you get a runtime error that says: "RuntimeError: Expected tensor for argument #1 'indices' to have scalar type Long".
## simply uncomment run the following lines of code additionally
# train_X = train_X.astype('int64')
# train_y = train_y.astype('int64')
# validation_X = validation_X.astype('int64')
# validation_y = validation_y.astype('int64')
# generate torch datasets
train_dataset = TensorDataset(torch.from_numpy(train_X).to(device), torch.from_numpy(train_y).to(device))
validation_dataset = TensorDataset(torch.from_numpy(validation_X).to(device), torch.from_numpy(validation_y).to(device))
batch_size = 32
# torch dataloaders (shuffle data)
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
validation_dataloader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=True)
# get a batch of train data
train_data_iter = iter(train_dataloader)
X_example, y_example = train_data_iter.next()
print('Example Input size: ', X_example.size()) # batch_size, seq_length
print('Example Input:\n', X_example)
print()
print('Example Output size: ', y_example.size()) # batch_size
print('Example Output:\n', y_example)
Example Input size: torch.Size([32, 512])
Example Input:
tensor([[ 0, 0, 0, ..., 1, 875, 520],
[ 0, 0, 0, ..., 482, 800, 1794],
[ 0, 0, 0, ..., 3, 1285, 70251],
...,
[ 0, 0, 0, ..., 4, 1, 1374],
[ 0, 0, 0, ..., 2, 8268, 17117],
[ 0, 0, 0, ..., 6429, 271, 116]])
Example Output size: torch.Size([32])
Example Output:
tensor([1., 0., 1., 0., 0., 1., 0., 1., 1., 0., 1., 1., 0., 0., 0., 1., 1., 1.,
1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1.])
모델 인스턴스화 및 훈련¶
class RNN(nn.Module):
def __init__(self, input_dimension, embedding_dimension, hidden_dimension, output_dimension):
super().__init__()
self.embedding_layer = nn.Embedding(input_dimension, embedding_dimension)
self.rnn_layer = nn.RNN(embedding_dimension, hidden_dimension, num_layers=1)
self.fc_layer = nn.Linear(hidden_dimension, output_dimension)
def forward(self, sequence):
# sequence shape = (sequence_length, batch_size)
embedding = self.embedding_layer(sequence)
# embedding shape = [sequence_length, batch_size, embedding_dimension]
output, hidden_state = self.rnn_layer(embedding)
# output shape = [sequence_length, batch_size, hidden_dimension]
# hidden_state shape = [1, batch_size, hidden_dimension]
final_output = self.fc_layer(hidden_state[-1,:,:].squeeze(0))
return final_output
# RNN Model
input_dimension = len(vocab_to_token)+1 # +1 to account for padding
embedding_dimension = 100
hidden_dimension = 32
output_dimension = 1
rnn_model = RNN(input_dimension, embedding_dimension, hidden_dimension, output_dimension)
optim = torch.optim.Adam(rnn_model.parameters())
loss_func = nn.BCEWithLogitsLoss()
rnn_model = rnn_model.to(device)
loss_func = loss_func.to(device)
임베딩 계층으로 시작해 RNN 계층,마지막으로 완전 연결 계층으로 이어지는 전체 RNN 모델을 인스턴스화했다.
def accuracy_metric(predictions, ground_truth):
"""
Returns 0-1 accuracy for the given set of predictions and ground truth
"""
# round predictions to either 0 or 1
rounded_predictions = torch.round(torch.sigmoid(predictions))
success = (rounded_predictions == ground_truth).float() #convert into float for division
accuracy = success.sum() / len(success)
return accuracy
def train(model, dataloader, optim, loss_func):
loss = 0
accuracy = 0
model.train()
for sequence, sentiment in dataloader:
optim.zero_grad()
preds = model(sequence.T).squeeze()
loss_curr = loss_func(preds, sentiment)
accuracy_curr = accuracy_metric(preds, sentiment)
loss_curr.backward()
optim.step()
loss += loss_curr.item()
accuracy += accuracy_curr.item()
return loss/len(dataloader), accuracy/len(dataloader)
def validate(model, dataloader, loss_func):
loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for sequence, sentiment in dataloader:
preds = model(sequence.T).squeeze()
loss_curr = loss_func(preds, sentiment)
accuracy_curr = accuracy_metric(preds, sentiment)
loss += loss_curr.item()
accuracy += accuracy_curr.item()
return loss/len(dataloader), accuracy/len(dataloader)
num_epochs = 10
best_validation_loss = float('inf')
for ep in range(num_epochs):
time_start = time.time()
training_loss, train_accuracy = train(rnn_model, train_dataloader, optim, loss_func)
validation_loss, validation_accuracy = validate(rnn_model, validation_dataloader, loss_func)
time_end = time.time()
time_delta = time_end - time_start
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
torch.save(rnn_model.state_dict(), 'rnn_model.pt')
print(f'epoch number: {ep+1} | time elapsed: {time_delta}s')
print(f'training loss: {training_loss:.3f} | training accuracy: {train_accuracy*100:.2f}%')
print(f'validation loss: {validation_loss:.3f} | validation accuracy: {validation_accuracy*100:.2f}%')
print()
epoch number: 1 | time elapsed: 136.13723397254944s
training loss: 0.627 | training accuracy: 66.23%
validation loss: 1.048 | validation accuracy: 19.65%
epoch number: 2 | time elapsed: 150.36637210845947s
training loss: 0.533 | training accuracy: 73.80%
validation loss: 0.858 | validation accuracy: 54.43%
epoch number: 3 | time elapsed: 186.54570603370667s
training loss: 0.438 | training accuracy: 80.39%
validation loss: 0.551 | validation accuracy: 78.56%
epoch number: 4 | time elapsed: 178.38556694984436s
training loss: 0.383 | training accuracy: 83.26%
validation loss: 0.915 | validation accuracy: 57.72%
epoch number: 5 | time elapsed: 184.10346102714539s
training loss: 0.334 | training accuracy: 86.46%
validation loss: 1.001 | validation accuracy: 56.94%
epoch number: 6 | time elapsed: 180.75322008132935s
training loss: 0.299 | training accuracy: 88.33%
validation loss: 1.164 | validation accuracy: 54.97%
epoch number: 7 | time elapsed: 189.0122902393341s
training loss: 0.266 | training accuracy: 89.62%
validation loss: 1.133 | validation accuracy: 60.51%
epoch number: 8 | time elapsed: 199.3309519290924s
training loss: 0.198 | training accuracy: 92.92%
validation loss: 0.971 | validation accuracy: 66.19%
epoch number: 9 | time elapsed: 185.76586294174194s
training loss: 0.315 | training accuracy: 87.93%
validation loss: 0.950 | validation accuracy: 62.34%
epoch number: 10 | time elapsed: 188.91670608520508s
training loss: 0.193 | training accuracy: 93.08%
validation loss: 1.042 | validation accuracy: 62.71%
def sentiment_inference(model, sentence):
model.eval()
# text transformations
sentence = sentence.lower()
sentence = ''.join([c for c in sentence if c not in punctuation])
tokenized = [vocab_to_token.get(token, 0) for token in sentence.split()]
tokenized = np.pad(tokenized, (512-len(tokenized), 0), 'constant')
# model inference
model_input = torch.LongTensor(tokenized).to(device)
model_input = model_input.unsqueeze(1)
pred = torch.sigmoid(model(model_input))
return pred.item()
print(sentiment_inference(rnn_model, "This film is horrible"))
print(sentiment_inference(rnn_model, "Director tried too hard but this film is bad"))
print(sentiment_inference(rnn_model, "Decent movie, although could be shorter"))
print(sentiment_inference(rnn_model, "This film will be houseful for weeks"))
print(sentiment_inference(rnn_model, "I loved the movie, every part of it"))
0.05216024070978165
0.17682921886444092
0.7510029077529907
0.9689022898674011
0.9829260110855103
LSTM을 이용한 감성분석 : Pytouch
RNN에 비해서 학습에 오랜 시간이 필요하지만, 중요한 정보는 보존하고 최근 정보라도 관련 없는 정보는 '망각'하는 데 도움이 되는 메모리 셀 게이트 덕분에 더 긴 시퀀스를 잘 처리할 수 있기에 이전 실습에서 나타난 과적합 부분을 'Drop out'을 사용하여 학습을 진행해보았다.
import os
import time
import numpy as np
from tqdm import tqdm
from string import punctuation
from collections import Counter
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(123)
<torch._C.Generator at 0x194d0ece110>import random
from torchtext import (data, datasets)
리뷰 텍스트와 감성 레이블 두개의 필드로 나누어줌.
TEXT_FIELD = data.Field(tokenize = data.get_tokenizer("basic_english"), include_lengths = True)
LABEL_FIELD = data.LabelField(dtype = torch.float)
train_dataset, test_dataset = datasets.IMDB.splits(TEXT_FIELD, LABEL_FIELD)
train_dataset, valid_dataset = train_dataset.split(random_state = random.seed(123))
downloading aclImdb_v1.tar.gz
.data\imdb\aclImdb_v1.tar.gz: 100%|███████████████████████████████████████████████| 84.1M/84.1M [00:10<00:00, 7.88MB/s]
touchtext.data.Field와 touchtext.data.LabelField의 build_vocab 메서드 사용하여, 사전 정의
MAX_VOCABULARY_SIZE = 25000
TEXT_FIELD.build_vocab(train_dataset,
max_size = MAX_VOCABULARY_SIZE)
LABEL_FIELD.build_vocab(train_dataset)
B_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data_iterator, valid_data_iterator, test_data_iterator = data.BucketIterator.splits(
(train_dataset, valid_dataset, test_dataset),
batch_size = B_SIZE,
sort_within_batch = True,
device = device)
## If you are training using GPUs, we need to use the following function for the pack_padded_sequence method to work
## (reference : https://discuss.pytorch.org/t/error-with-lengths-in-pack-padded-sequence/35517/3)
if torch.cuda.is_available():
torch.set_default_tensor_type(torch.cuda.FloatTensor)
from torch.nn.utils.rnn import pack_padded_sequence, PackedSequence
def cuda_pack_padded_sequence(input, lengths, batch_first=False, enforce_sorted=True):
lengths = torch.as_tensor(lengths, dtype=torch.int64)
lengths = lengths.cpu()
if enforce_sorted:
sorted_indices = None
else:
lengths, sorted_indices = torch.sort(lengths, descending=True)
sorted_indices = sorted_indices.to(input.device)
batch_dim = 0 if batch_first else 1
input = input.index_select(batch_dim, sorted_indices)
data, batch_sizes = \
torch._C._VariableFunctions._pack_padded_sequence(input, lengths, batch_first)
return PackedSequence(data, batch_sizes, sorted_indices)
class LSTM(nn.Module):
def __init__(self, vocabulary_size, embedding_dimension, hidden_dimension, output_dimension, dropout, pad_index):
super().__init__()
self.embedding_layer = nn.Embedding(vocabulary_size, embedding_dimension, padding_idx = pad_index)
self.lstm_layer = nn.LSTM(embedding_dimension,
hidden_dimension,
num_layers=1,
bidirectional=True,
dropout=dropout)
self.fc_layer = nn.Linear(hidden_dimension * 2, output_dimension)
self.dropout_layer = nn.Dropout(dropout)
def forward(self, sequence, sequence_lengths=None):
if sequence_lengths is None:
sequence_lengths = torch.LongTensor([len(sequence)])
# sequence := (sequence_length, batch_size)
embedded_output = self.dropout_layer(self.embedding_layer(sequence))
# embedded_output := (sequence_length, batch_size, embedding_dimension)
if torch.cuda.is_available():
packed_embedded_output = cuda_pack_padded_sequence(embedded_output, sequence_lengths)
else:
packed_embedded_output = nn.utils.rnn.pack_padded_sequence(embedded_output, sequence_lengths)
packed_output, (hidden_state, cell_state) = self.lstm_layer(packed_embedded_output)
# hidden_state := (num_layers * num_directions, batch_size, hidden_dimension)
# cell_state := (num_layers * num_directions, batch_size, hidden_dimension)
op, op_lengths = nn.utils.rnn.pad_packed_sequence(packed_output)
# op := (sequence_length, batch_size, hidden_dimension * num_directions)
hidden_output = torch.cat((hidden_state[-2,:,:], hidden_state[-1,:,:]), dim = 1)
# hidden_output := (batch_size, hidden_dimension * num_directions)
return self.fc_layer(hidden_output)
INPUT_DIMENSION = len(TEXT_FIELD.vocab)
EMBEDDING_DIMENSION = 100
HIDDEN_DIMENSION = 32
OUTPUT_DIMENSION = 1
DROPOUT = 0.5
PAD_INDEX = TEXT_FIELD.vocab.stoi[TEXT_FIELD.pad_token]
lstm_model = LSTM(INPUT_DIMENSION,
EMBEDDING_DIMENSION,
HIDDEN_DIMENSION,
OUTPUT_DIMENSION,
DROPOUT,
PAD_INDEX)
C:\Users\sk8er\anaconda3\envs\mpytc\lib\site-packages\torch\nn\modules\rnn.py:50: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.5 and num_layers=1
"num_layers={}".format(dropout, num_layers))
UNK_INDEX = TEXT_FIELD.vocab.stoi[TEXT_FIELD.unk_token]
lstm_model.embedding_layer.weight.data[UNK_INDEX] = torch.zeros(EMBEDDING_DIMENSION)
lstm_model.embedding_layer.weight.data[PAD_INDEX] = torch.zeros(EMBEDDING_DIMENSION)
optim = torch.optim.Adam(lstm_model.parameters())
loss_func = nn.BCEWithLogitsLoss()
lstm_model = lstm_model.to(device)
loss_func = loss_func.to(device)
def accuracy_metric(predictions, ground_truth):
"""
Returns 0-1 accuracy for the given set of predictions and ground truth
"""
# round predictions to either 0 or 1
rounded_predictions = torch.round(torch.sigmoid(predictions))
success = (rounded_predictions == ground_truth).float() #convert into float for division
accuracy = success.sum() / len(success)
return accuracy
def train(model, data_iterator, optim, loss_func):
loss = 0
accuracy = 0
model.train()
for curr_batch in data_iterator:
optim.zero_grad()
sequence, sequence_lengths = curr_batch.text
preds = lstm_model(sequence, sequence_lengths).squeeze(1)
loss_curr = loss_func(preds, curr_batch.label)
accuracy_curr = accuracy_metric(preds, curr_batch.label)
loss_curr.backward()
optim.step()
loss += loss_curr.item()
accuracy += accuracy_curr.item()
return loss/len(data_iterator), accuracy/len(data_iterator)
def validate(model, data_iterator, loss_func):
loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for curr_batch in data_iterator:
sequence, sequence_lengths = curr_batch.text
preds = model(sequence, sequence_lengths).squeeze(1)
loss_curr = loss_func(preds, curr_batch.label)
accuracy_curr = accuracy_metric(preds, curr_batch.label)
loss += loss_curr.item()
accuracy += accuracy_curr.item()
return loss/len(data_iterator), accuracy/len(data_iterator)
num_epochs = 10
best_validation_loss = float('inf')
for ep in range(num_epochs):
time_start = time.time()
training_loss, train_accuracy = train(lstm_model, train_data_iterator, optim, loss_func)
validation_loss, validation_accuracy = validate(lstm_model, valid_data_iterator, loss_func)
time_end = time.time()
time_delta = time_end - time_start
if validation_loss < best_validation_loss:
best_validation_loss = validation_loss
torch.save(lstm_model.state_dict(), 'lstm_model.pt')
print(f'epoch number: {ep+1} | time elapsed: {time_delta}s')
print(f'training loss: {training_loss:.3f} | training accuracy: {train_accuracy*100:.2f}%')
print(f'validation loss: {validation_loss:.3f} | validation accuracy: {validation_accuracy*100:.2f}%')
print()
epoch number: 1 | time elapsed: 10.499292135238647s
training loss: 0.688 | training accuracy: 54.09%
validation loss: 0.674 | validation accuracy: 58.18%
epoch number: 2 | time elapsed: 10.434584379196167s
training loss: 0.663 | training accuracy: 60.19%
validation loss: 0.611 | validation accuracy: 66.78%
epoch number: 3 | time elapsed: 10.492015361785889s
training loss: 0.591 | training accuracy: 68.11%
validation loss: 0.620 | validation accuracy: 71.48%
epoch number: 4 | time elapsed: 10.2067391872406s
training loss: 0.529 | training accuracy: 73.84%
validation loss: 0.588 | validation accuracy: 74.06%
epoch number: 5 | time elapsed: 10.220768213272095s
training loss: 0.471 | training accuracy: 77.72%
validation loss: 0.655 | validation accuracy: 73.51%
epoch number: 6 | time elapsed: 10.350415468215942s
training loss: 0.426 | training accuracy: 80.57%
validation loss: 0.562 | validation accuracy: 78.74%
epoch number: 7 | time elapsed: 10.357213735580444s
training loss: 0.391 | training accuracy: 82.64%
validation loss: 0.637 | validation accuracy: 76.60%
epoch number: 8 | time elapsed: 10.276661396026611s
training loss: 0.377 | training accuracy: 83.39%
validation loss: 0.543 | validation accuracy: 80.62%
epoch number: 9 | time elapsed: 10.23417329788208s
training loss: 0.353 | training accuracy: 84.77%
validation loss: 0.506 | validation accuracy: 78.40%
epoch number: 10 | time elapsed: 10.402759075164795s
training loss: 0.325 | training accuracy: 86.44%
validation loss: 0.557 | validation accuracy: 79.22%
#lstm_model.load_state_dict(torch.load('../../mastering_pytorch_packt/04_deep_recurrent_net_architectures/lstm_model.pt'))
lstm_model.load_state_dict(torch.load('lstm_model.pt'))
test_loss, test_accuracy = validate(lstm_model, test_data_iterator, loss_func)
print(f'test loss: {test_loss:.3f} | test accuracy: {test_accuracy*100:.2f}%')
test loss: 0.544 | test accuracy: 77.04%
def sentiment_inference(model, sentence):
model.eval()
# text transformations
tokenized = data.get_tokenizer("basic_english")(sentence)
tokenized = [TEXT_FIELD.vocab.stoi[t] for t in tokenized]
# model inference
model_input = torch.LongTensor(tokenized).to(device)
model_input = model_input.unsqueeze(1)
pred = torch.sigmoid(model(model_input))
return pred.item()
print(sentiment_inference(lstm_model, "This film is horrible"))
print(sentiment_inference(lstm_model, "Director tried too hard but this film is bad"))
print(sentiment_inference(lstm_model, "Decent movie, although could be shorter"))
print(sentiment_inference(lstm_model, "This film will be houseful for weeks"))
print(sentiment_inference(lstm_model, "I loved the movie, every part of it"))
0.07853574305772781
0.01614055596292019
0.325915664434433
0.8385397791862488
0.942153811454773