[ML] 앙상블 학습(Ensemble Learning)
앙상블 학습(Ensemble Learning)
앙상블 학습이란?
앙상블 학습(Ensemble Learning)을 통한 분류는 여러 개의 분류기(Classifier)를 생성하고,
그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법임
어려운 문제의 결론을 내기 위해 여러 명의 전문가로 위원회를 구성해 다양한 의견을 수렴하고 결정하듯이
앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것이다.
앙상블 유형
일반적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)으로 구분할 수 있으며, 이외에 스태킹(Stacking)등의 기법이 있다.
대표적 배깅은 랜덤포레스트 알고리즘이 있으며, 부스팅은 에이다 부스팅, 그래디언트 부스팅, XGBoost, LightGBM등이 있다.
정형 데이터의 분류나 회귀에서는 GBM 부스팅 계열의 앙상블이 전반적으로 높은 예측 성능을 나타낸다.
앙상블의 특징
- 단일 모델의 약점을 다수의 모델들을 결합하여 보완함.
- 뛰어난 서능을 가진 모델들로만 구성하는 것보다는 성능이 떨어지더라도
- 서로 다른 유형의 모델을 섞는 것이 오히려 전체 성능이 도움이 될 수 있음
- 랜덤 포레스트 및 뛰어난 부스팅 알고리즘들은 모두 결정 트리 알고리즘을 기반 알고리즘으로 적용함.
- 결정 트리의 단점인 과적함(Overfiting)을 수십 ~ 수천개의 많은 분류기를 결합해 보완하고
- 장점인 직관적인 분류 기준은 강화됨
보팅(Voting)과 배깅(Bagging)
보팅의 경우 일반적으로 서로 다른 알고리즘(kn,LinearRegrssion 등)을 가진 분류기를 결합하는 것이고
배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게
가져가면서 학습을 수행해 보팅을 수행함.
즉, 배깅은 같은 알고리즘을 가진 분류기 이지만, 샘플 데이터를 서로 다르게 하여 이를 어셈블하는 형태

보팅 유형 - Hard Vothing / Soft Vothing
- Hard Voting 같은 경우 다수결과 비슷한 방식으로 예측을 수행함
Classifier1 ->2 / Classifier2 ->2 / Classifier3 ->1 / Classifier4 ->2
예측을 진행한다면, 2로 결론을 내는 방식임 - Soft Voting 같은 경우는 class별 확률들을 평균으로 하여 결정함
Classifier1 이 값 1로 예측한 확률 0.34, 2로 예측한 확률 0.65 / Classifier2 이
1로 예측한 확률 0.45, 2로 예측한 확률 0.48 이라면 각각 1과2로 예측한 확률들을 평균으로하여 값을 결정한다.
-> 일반적으로 Soft Vothing의 경우가 예측 성능이 우수하여 주로 사용하고, 사이킷런은 VothingClassifier 클래를 통해 Vothing을 지원함
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
cancer = load_breast_cancer()
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression(solver='liblinear')
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR',lr_clf),('KNN',knn_clf)] , voting='soft' )
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size=0.2 , random_state= 156)
# VotingClassifier 학습/예측/평가.
vo_clf.fit(X_train , y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
# 개별 모델의 학습/예측/평가.
classifiers = [lr_clf, knn_clf]
for classifier in classifiers:
classifier.fit(X_train , y_train)
pred = classifier.predict(X_test)
class_name= classifier.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name, accuracy_score(y_test , pred)))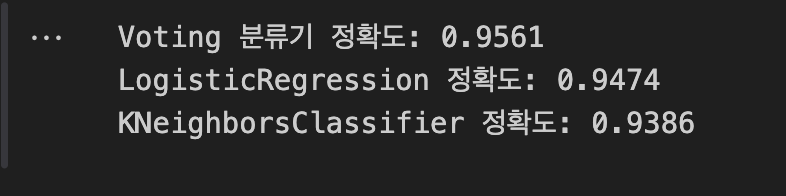
Random Forest
배깅(Bagging) - RandomForestModel
배깅의 대표적인 알고리즘은 랜덤 포레스트임 / XgBoost, LightGBM 이전에는 가장 좋은 성능
앙상블 알고리즘 중 비교적 빠른 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있음
결정 트리를 랜덤하게 여러개를 만들어서 숲 형태를 만드는 것 (랜덤으로 트리를 만든다는 것이 Point)
-> 각각의 다른 샘플링(부트스트래핑)을하여 다른 서브세트로 배깅을 진행하고, 보팅을 통해 예측결정을 하게됨
부트스트래핑 방식은 보통 데이터 셋 크기에 마춰 분활을 진행하고, 만약 이보다 줄일경우에는 정확도가 떨어질 가능성이 높음

사이킷런 RandomForest 하이퍼 파라미터
- n_estimators : 결정 트리의 개수를 지정함 / 디폴트는 100 개이며, 많은 수록 좋은 성능을 기대할 수 있지만, 무작정 높일 수록 성능 향상이 나오는 것은 아님
- max_features : 결정 트리에 사용된 max_features 파라미터와 같지만, 디폴트는 'None'이 아니라, 'auto'이며 즉, 'sqrt'와 같다. 따라서 피처가 16개일 경우 4개를 사용하는 것과 같음
- max_depth 와 min_samples_leaf와 같이 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터도 사용가능
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9973541965122431 0.8903229806766861rf.fit(train_input, train_target)
print(rf.feature_importances_)[0.23183515 0.50059756 0.26756729]rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)0.8945545507023283Extra Tree
RandomForst와 다르게 부스트스트랩 샘플을 사용하지않고 데이터를 모두 사용함
또한, 분활 자체를 랜덤하게 분활하고 이중에서 best를 찾음 (무작위로 랜덤으로 분활하기 때문에 속도가 빠르지만, 성능적 측면에서 다소 떨어짐)
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9974503966084433 0.8887848893166506et.fit(train_input, train_target)
print(et.feature_importances_)[0.20183568 0.52242907 0.27573525]Gradient Boosting
여러 개의 약한 학습기(Week learner)를 조합하여 강력한 예측 모델을 만드는 앙상블 학습 방법
핵심 아이디어는 이전 학습기의 오차를 보완하여 새로운 학습기를 순차적으로 학습시키는 것
이전 학습기의 오차에 대한 Gradient(기울기)를 계산하고, 다음 학습기를 이 Gradient 정보를 기반으로 업데이트하여 오차를 줄임
(leaning rate로 하강의 속도를 조절하며 max_depth를 통해서 오버피팅을 줄임)
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(random_state=42)
#return_train_score를 True를 함으로써 score를 확인함
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.8881086892152563 0.8720430147331015아래와 같이 learning_rate를 늘렸을때 train_data의 정확도는 올라갔으나 검증세트의 정확도는 미미하다.
너무 과도하게 훈련하면, 검증 세트가 과대적합되기 때문에 급격하게 검증세트의 점수가 낮아질 수 있다.
하지만, 트리의 경우에는 급격한 정확도가 떨어지는 것을 막을 수 있는 것이 특징
(이전에는 epoch로 볼 수 있었으나, Tree의 경우 tree의 개수로 이를 확인해 볼 수 있음)
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))0.9464595437171814 0.8780082549788999gb.fit(train_input, train_target)
print(gb.feature_importances_)[0.15872278 0.68010884 0.16116839]XGBoost
- Gradient Boosting을 기반으로 하며, 정규화된 손실함수를 계산하여,즉, 이전 모델에서의 실제 값과 예측값의 오차(loss)를 훈련 데이터에 투입하고 gradient를 이용해서 보완하는 방식을 사용**☑︎ 중요**L1,L2규제를 따로 진행시켜주지 않아도 된다.]
- (생각해보아야 할 것은 정규화 된 손실함수를 계산하는 것이 어떤 이점을 주는가에 대해서 고민해보자)
- -> XGBoost 와 LightGBM은 정규화된 손실 함수를 계산하여 오차를 줄여나가기 때문에, Gradient Boost와 다르게
- (결정 트리 알고리즘을 사용하며,이를 최적화한 "CART"트리를 활용하여 발전된 트리 모델을 생성)
- 이전 모델의 오류를 순차적으로 보완해나가는 방식으로 모델을 형성하는 것이다.
XGBoost 하이퍼 파라미터
General Parameters (XGBoost의 어떤 모델을 사용할 것인가?)
- booster [default = 'gbtree']gblinear -> 선형 모델
- gbtree -> 트리 기반 모델
- silent [default = 0]1 -> 동작 메세지 프린트 안함
- 0 -> 동작 메세지 프린트함
- nthread [default = 전체 사용]
Booster Parameters (모델 조건 설정)
- n_estimators[default=100] -> 나무의 개수 (=num_boost_round[default=10] -> 파이썬 래퍼에서 적용)
- ealry_stopping_rounds과적합을 방지할 수 있고, n_estimators가 높을 때 주로 사용
- 최대한 몇개의 트리를 완성할 것인가? / vaild loss(손실값)에 더이상 향상이 없으면 멈춤
- learning_rate[default =0.1] (=eta [default=0.3]: 파이썬 래퍼에서 적용)낮은 eta -> 낮은 가중치 -> 다음 단계의 결과물에 영향 적음 -> 보수적gradient boost에서는 기울기를 의미하며 작으면 꼼꼼히 내려가고 크면 급하게 되려가는 것을 의미함 (헷갈리지 않기!)
- 일반적으로 0.01~0.2
- 학습 단계별로 가중치를 얼마만큼 사용할지 결정 / 이전결과를 얼마나 반영할 것인지의 값
- min_child_weight [default = 1]이 값보다 샘플 수가 작으면 leaf node가 되는 것CV로 조절해야함
- 너무 크면 under-fitting 될 수 있음
- child 에서 필요한 모든 관측치에 대한 가중치의 최소 합
- max_depth [default = 6]일반적으로 3 ~ 10
- CV로 조절해야함
- 트리의 최대 깊이
- gamma [default = 0]값이 클수록 과적합 감소 효과
- 트리에서 추가적으로 가지를 나눌지를 결정할 최소 손실 감소 값
- subsample [default = 1] (=sub_sample : 파이썬 래퍼에서 적용)over-fitting 방지
- 일반적으로 0.5 ~ 1
- 각 트리마다 데이터 샘플링 비율
- **colsample_bytree [default = 1]일반적으로 0.5 ~ 1
- 각 트리마다 feature 샘플링 비율
- reg_lambda [default = 1] (=lambda : 파이썬 래퍼에서 적용)클수록 보수적
- L2 regularization(ex. 릿지) 가중치
- reg_alpha [default = 0] (=alpha : 파이썬 래퍼에서 적용)클수록 보수적
- 특성이 매우 많은때 사용해볼만 함
- L1 regularization(ex. 라쏘) 가중치
- scale_pos_weight [default = 1]보통 값을 음성 데이터 수/ 양성 데이터 수 값으로 함
- 데이터가 불균형할때 사용, 0보다 큰 값
Leaning Task Parameters (모델의 목표 및 계산 방법 설정)
- objective [default = reg:linear] (목적 함수)multi:softmax : softmax를 사용한 다중 클래스 분류, 확률이 아닌 예측된 클래스 반환
- multi:softprob : softmax와 같지만 각 클래스에 대한 예상 확률 반환
- binary:logistic :이진 분류를 위한 로지스틱 회귀, 클래스가 아닌 예측된 확률 반환
- eval_metric [목적 함수에 따라 디폴트 값이 다름(회귀-rmse / 분류-error)]mae : mean absolute errorerror : binary classificaion error rate (임계값 0.5)mlogloss : multiclass logloss
- auc : area under the curve
- merror : multiclass classification error rate
- logloss : negative log-likelihood
- rmse : root mean square error
- seed [default = 0]
- 시드값 고정 (나중에 재현할때 같은 값을 출력하기 위해)
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
# xgboost 패키지 로딩하기
import xgboost as xgb
from xgboost import plot_importance
import warnings
warnings.filterwarnings('ignore')
dataset = load_breast_cancer()
features= dataset.data
labels = dataset.target
cancer_df = pd.DataFrame(data=features, columns=dataset.feature_names)
cancer_df['target']= labels
cancer_df.head(3)| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.8 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.6 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.9 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.8 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.0 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.5 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
3 rows × 31 columns
print(dataset.target_names)
print(cancer_df['target'].value_counts())['malignant' 'benign']
1 357
0 212
Name: target, dtype: int64# cancer_df에서 feature용 DataFrame과 Label용 Series 객체 추출
# 맨 마지막 칼럼이 Label이므로 Feature용 DataFrame은 cancer_df의 첫번째 칼럼에서 맨 마지막 두번째 컬럼까지를 :-1 슬라이싱으로 추출.
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label, test_size=0.2, random_state=156 )
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train, test_size=0.1, random_state=156 )
print(X_train.shape , X_test.shape)
print(X_tr.shape, X_val.shape)(455, 30) (114, 30)
(409, 30) (46, 30)학습과 예측 데이터 세트를 DMatrix로 변환
- DMatrix는 넘파이 array, DataFrame에서도 변환 가능
# 만약 구버전 XGBoost에서 DataFrame으로 DMatrix 생성이 안될 경우 X_train.values로 넘파이 변환.
# 학습, 검증, 테스트용 DMatrix를 생성.
dtr = xgb.DMatrix(data=X_tr, label=y_tr)
dval = xgb.DMatrix(data=X_val, label=y_val)
dtest = xgb.DMatrix(data=X_test , label=y_test)params = { 'max_depth':3,
'eta': 0.05,
'objective':'binary:logistic',
'eval_metric':'logloss'
}
num_rounds = 400주어진 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달하고 학습
# 학습 데이터 셋은 'train' 또는 평가 데이터 셋은 'eval' 로 명기합니다.
eval_list = [(dtr,'train'),(dval,'eval')] # 또는 eval_list = [(dval,'eval')] 만 명기해도 무방.
# 하이퍼 파라미터와 early stopping 파라미터를 train( ) 함수의 파라미터로 전달
xgb_model = xgb.train(params = params , dtrain=dtr , num_boost_round=num_rounds , \
early_stopping_rounds=50, evals=eval_list )[0] train-logloss:0.65016 eval-logloss:0.66183
[1] train-logloss:0.61131 eval-logloss:0.63609
[2] train-logloss:0.57563 eval-logloss:0.61144
[3] train-logloss:0.54310 eval-logloss:0.59204
[4] train-logloss:0.51323 eval-logloss:0.57329
[5] train-logloss:0.48447 eval-logloss:0.55037
[6] train-logloss:0.45796 eval-logloss:0.52930
[7] train-logloss:0.43436 eval-logloss:0.51534
[8] train-logloss:0.41150 eval-logloss:0.49718
[9] train-logloss:0.39027 eval-logloss:0.48154
[10] train-logloss:0.37128 eval-logloss:0.46990
[11] train-logloss:0.35254 eval-logloss:0.45474
[12] train-logloss:0.33528 eval-logloss:0.44229
[13] train-logloss:0.31892 eval-logloss:0.42961
[14] train-logloss:0.30439 eval-logloss:0.42065
[15] train-logloss:0.29000 eval-logloss:0.40958
[16] train-logloss:0.27651 eval-logloss:0.39887
[17] train-logloss:0.26389 eval-logloss:0.39050
[18] train-logloss:0.25210 eval-logloss:0.38254
[19] train-logloss:0.24123 eval-logloss:0.37393
[20] train-logloss:0.23076 eval-logloss:0.36789
[21] train-logloss:0.22091 eval-logloss:0.36017
[22] train-logloss:0.21155 eval-logloss:0.35421
[23] train-logloss:0.20263 eval-logloss:0.34683
[24] train-logloss:0.19434 eval-logloss:0.34111
[25] train-logloss:0.18637 eval-logloss:0.33634
[26] train-logloss:0.17875 eval-logloss:0.33082
[27] train-logloss:0.17167 eval-logloss:0.32675
[28] train-logloss:0.16481 eval-logloss:0.32099
[29] train-logloss:0.15835 eval-logloss:0.31671
[30] train-logloss:0.15225 eval-logloss:0.31277
[31] train-logloss:0.14650 eval-logloss:0.30882
[32] train-logloss:0.14102 eval-logloss:0.30437
[33] train-logloss:0.13590 eval-logloss:0.30103
[34] train-logloss:0.13109 eval-logloss:0.29794
[35] train-logloss:0.12647 eval-logloss:0.29499
[36] train-logloss:0.12197 eval-logloss:0.29295
[37] train-logloss:0.11784 eval-logloss:0.29043
[38] train-logloss:0.11379 eval-logloss:0.28927
[39] train-logloss:0.10994 eval-logloss:0.28578
[40] train-logloss:0.10638 eval-logloss:0.28364
[41] train-logloss:0.10302 eval-logloss:0.28183
[42] train-logloss:0.09963 eval-logloss:0.28005
[43] train-logloss:0.09649 eval-logloss:0.27972
[44] train-logloss:0.09359 eval-logloss:0.27744
[45] train-logloss:0.09080 eval-logloss:0.27542
[46] train-logloss:0.08807 eval-logloss:0.27504
[47] train-logloss:0.08541 eval-logloss:0.27458
[48] train-logloss:0.08299 eval-logloss:0.27348
[49] train-logloss:0.08035 eval-logloss:0.27247
[50] train-logloss:0.07786 eval-logloss:0.27163
[51] train-logloss:0.07550 eval-logloss:0.27094
[52] train-logloss:0.07344 eval-logloss:0.26967
[53] train-logloss:0.07147 eval-logloss:0.27008
[54] train-logloss:0.06964 eval-logloss:0.26890
[55] train-logloss:0.06766 eval-logloss:0.26854
[56] train-logloss:0.06591 eval-logloss:0.26900
[57] train-logloss:0.06433 eval-logloss:0.26790
[58] train-logloss:0.06259 eval-logloss:0.26663
[59] train-logloss:0.06107 eval-logloss:0.26743
[60] train-logloss:0.05957 eval-logloss:0.26610
[61] train-logloss:0.05817 eval-logloss:0.26644
[62] train-logloss:0.05691 eval-logloss:0.26673
[63] train-logloss:0.05550 eval-logloss:0.26550
[64] train-logloss:0.05422 eval-logloss:0.26443
[65] train-logloss:0.05311 eval-logloss:0.26500
[66] train-logloss:0.05207 eval-logloss:0.26591
[67] train-logloss:0.05093 eval-logloss:0.26501
[68] train-logloss:0.04976 eval-logloss:0.26435
[69] train-logloss:0.04872 eval-logloss:0.26360
[70] train-logloss:0.04776 eval-logloss:0.26319
[71] train-logloss:0.04680 eval-logloss:0.26255
[72] train-logloss:0.04580 eval-logloss:0.26204
[73] train-logloss:0.04484 eval-logloss:0.26254
[74] train-logloss:0.04388 eval-logloss:0.26289
[75] train-logloss:0.04309 eval-logloss:0.26249
[76] train-logloss:0.04224 eval-logloss:0.26217
[77] train-logloss:0.04133 eval-logloss:0.26166
[78] train-logloss:0.04050 eval-logloss:0.26179
[79] train-logloss:0.03967 eval-logloss:0.26103
[80] train-logloss:0.03876 eval-logloss:0.26094
[81] train-logloss:0.03806 eval-logloss:0.26148
[82] train-logloss:0.03740 eval-logloss:0.26054
[83] train-logloss:0.03676 eval-logloss:0.25967
[84] train-logloss:0.03605 eval-logloss:0.25905
[85] train-logloss:0.03545 eval-logloss:0.26007
[86] train-logloss:0.03489 eval-logloss:0.25984
[87] train-logloss:0.03425 eval-logloss:0.25933
[88] train-logloss:0.03361 eval-logloss:0.25932
[89] train-logloss:0.03311 eval-logloss:0.26002
[90] train-logloss:0.03260 eval-logloss:0.25936
[91] train-logloss:0.03202 eval-logloss:0.25886
[92] train-logloss:0.03152 eval-logloss:0.25918
[93] train-logloss:0.03107 eval-logloss:0.25864
[94] train-logloss:0.03049 eval-logloss:0.25951
[95] train-logloss:0.03007 eval-logloss:0.26091
[96] train-logloss:0.02963 eval-logloss:0.26014
[97] train-logloss:0.02913 eval-logloss:0.25974
[98] train-logloss:0.02866 eval-logloss:0.25937
[99] train-logloss:0.02829 eval-logloss:0.25893
[100] train-logloss:0.02789 eval-logloss:0.25928
[101] train-logloss:0.02751 eval-logloss:0.25955
[102] train-logloss:0.02714 eval-logloss:0.25901
[103] train-logloss:0.02668 eval-logloss:0.25991
[104] train-logloss:0.02634 eval-logloss:0.25950
[105] train-logloss:0.02594 eval-logloss:0.25924
[106] train-logloss:0.02556 eval-logloss:0.25901
[107] train-logloss:0.02522 eval-logloss:0.25738
[108] train-logloss:0.02492 eval-logloss:0.25702
[109] train-logloss:0.02453 eval-logloss:0.25789
[110] train-logloss:0.02418 eval-logloss:0.25770
[111] train-logloss:0.02384 eval-logloss:0.25842
[112] train-logloss:0.02356 eval-logloss:0.25810
[113] train-logloss:0.02322 eval-logloss:0.25848
[114] train-logloss:0.02290 eval-logloss:0.25833
[115] train-logloss:0.02260 eval-logloss:0.25820
[116] train-logloss:0.02229 eval-logloss:0.25905
[117] train-logloss:0.02204 eval-logloss:0.25878
[118] train-logloss:0.02176 eval-logloss:0.25728
[119] train-logloss:0.02149 eval-logloss:0.25722
[120] train-logloss:0.02119 eval-logloss:0.25764
[121] train-logloss:0.02095 eval-logloss:0.25761
[122] train-logloss:0.02067 eval-logloss:0.25832
[123] train-logloss:0.02045 eval-logloss:0.25808
[124] train-logloss:0.02023 eval-logloss:0.25855
[125] train-logloss:0.01998 eval-logloss:0.25714
[126] train-logloss:0.01973 eval-logloss:0.25587
[127] train-logloss:0.01946 eval-logloss:0.25640
[128] train-logloss:0.01927 eval-logloss:0.25685
[129] train-logloss:0.01908 eval-logloss:0.25665
[130] train-logloss:0.01886 eval-logloss:0.25712
[131] train-logloss:0.01863 eval-logloss:0.25609
[132] train-logloss:0.01839 eval-logloss:0.25649
[133] train-logloss:0.01816 eval-logloss:0.25789
[134] train-logloss:0.01802 eval-logloss:0.25811
[135] train-logloss:0.01785 eval-logloss:0.25794
[136] train-logloss:0.01763 eval-logloss:0.25876
[137] train-logloss:0.01748 eval-logloss:0.25884
[138] train-logloss:0.01732 eval-logloss:0.25867
[139] train-logloss:0.01719 eval-logloss:0.25876
[140] train-logloss:0.01696 eval-logloss:0.25987
[141] train-logloss:0.01681 eval-logloss:0.25960
[142] train-logloss:0.01669 eval-logloss:0.25982
[143] train-logloss:0.01656 eval-logloss:0.25992
[144] train-logloss:0.01638 eval-logloss:0.26035
[145] train-logloss:0.01623 eval-logloss:0.26055
[146] train-logloss:0.01606 eval-logloss:0.26092
[147] train-logloss:0.01589 eval-logloss:0.26137
[148] train-logloss:0.01572 eval-logloss:0.25999
[149] train-logloss:0.01556 eval-logloss:0.26028
[150] train-logloss:0.01546 eval-logloss:0.26048
[151] train-logloss:0.01531 eval-logloss:0.26142
[152] train-logloss:0.01515 eval-logloss:0.26188
[153] train-logloss:0.01501 eval-logloss:0.26227
[154] train-logloss:0.01486 eval-logloss:0.26287
[155] train-logloss:0.01476 eval-logloss:0.26299
[156] train-logloss:0.01462 eval-logloss:0.26346
[157] train-logloss:0.01448 eval-logloss:0.26379
[158] train-logloss:0.01434 eval-logloss:0.26306
[159] train-logloss:0.01424 eval-logloss:0.26237
[160] train-logloss:0.01410 eval-logloss:0.26251
[161] train-logloss:0.01401 eval-logloss:0.26265
[162] train-logloss:0.01392 eval-logloss:0.26264
[163] train-logloss:0.01380 eval-logloss:0.26250
[164] train-logloss:0.01372 eval-logloss:0.26264
[165] train-logloss:0.01359 eval-logloss:0.26255
[166] train-logloss:0.01350 eval-logloss:0.26188
[167] train-logloss:0.01342 eval-logloss:0.26203
[168] train-logloss:0.01331 eval-logloss:0.26190
[169] train-logloss:0.01319 eval-logloss:0.26184
[170] train-logloss:0.01312 eval-logloss:0.26133
[171] train-logloss:0.01304 eval-logloss:0.26148
[172] train-logloss:0.01297 eval-logloss:0.26157
[173] train-logloss:0.01285 eval-logloss:0.26253
[174] train-logloss:0.01278 eval-logloss:0.26229
[175] train-logloss:0.01267 eval-logloss:0.26086predict()를 통해 예측 확률값을 반환하고 예측 값으로 변환
pred_probs = xgb_model.predict(dtest)
print('predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨')
print(np.round(pred_probs[:10],3))
# 예측 확률이 0.5 보다 크면 1 , 그렇지 않으면 0 으로 예측값 결정하여 List 객체인 preds에 저장
preds = [ 1 if x > 0.5 else 0 for x in pred_probs ]
print('예측값 10개만 표시:',preds[:10])predict( ) 수행 결과값을 10개만 표시, 예측 확률 값으로 표시됨
[0.845 0.008 0.68 0.081 0.975 0.999 0.998 0.998 0.996 0.001]
예측값 10개만 표시: [1, 0, 1, 0, 1, 1, 1, 1, 1, 0]pred_probsarray([0.8447872 , 0.00842587, 0.6796298 , 0.08113331, 0.9751338 ,
0.9988939 , 0.9983084 , 0.9980654 , 0.99637896, 0.00138468,
0.00252283, 0.00154995, 0.99780875, 0.99829525, 0.99691856,
0.9965521 , 0.99120796, 0.9982718 , 0.9970682 , 0.9978916 ,
0.00202923, 0.10774372, 0.00137198, 0.9989255 , 0.00107862,
0.7800014 , 0.00295459, 0.00154995, 0.9966723 , 0.05379276,
0.958738 , 0.00149019, 0.9700533 , 0.8656249 , 0.00678389,
0.00140975, 0.97810876, 0.99713576, 0.24059245, 0.9972307 ,
0.35760084, 0.99708337, 0.9919429 , 0.99659145, 0.9962838 ,
0.9179466 , 0.036952 , 0.997417 , 0.99325067, 0.99804085,
0.99648905, 0.00236221, 0.9979361 , 0.99784875, 0.9960328 ,
0.99391055, 0.9984106 , 0.99635327, 0.9967404 , 0.896291 ,
0.9967794 , 0.9520696 , 0.00349248, 0.00202715, 0.9980167 ,
0.98225844, 0.00349248, 0.99056447, 0.9972249 , 0.9978916 ,
0.00297725, 0.99731344, 0.00163038, 0.98887384, 0.9962419 ,
0.00137198, 0.9985329 , 0.9985329 , 0.99858946, 0.00131184,
0.00139682, 0.93810165, 0.9969139 , 0.99748176, 0.992568 ,
0.9906398 , 0.9914522 , 0.9930942 , 0.9830724 , 0.00137198,
0.19445673, 0.99830306, 0.00650652, 0.00560008, 0.99777275,
0.00793959, 0.02962515, 0.99509096, 0.00236221, 0.78849 ,
0.00614955, 0.00250252, 0.99592257, 0.99598455, 0.6040961 ,
0.9969748 , 0.99688077, 0.8580849 , 0.9966723 , 0.9985133 ,
0.6028515 , 0.97962165, 0.99558735, 0.9978284 ], dtype=float32)get_clf_eval( )을 통해 예측 평가
from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))get_clf_eval(y_test , preds, pred_probs)오차 행렬
[[34 3]
[ 2 75]]
정확도: 0.9561, 정밀도: 0.9615, 재현율: 0.9740, F1: 0.9677, AUC:0.9937Feature Importance 시각화
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(xgb_model, ax=ax)<AxesSubplot:title={'center':'Feature importance'}, xlabel='F score', ylabel='Features'>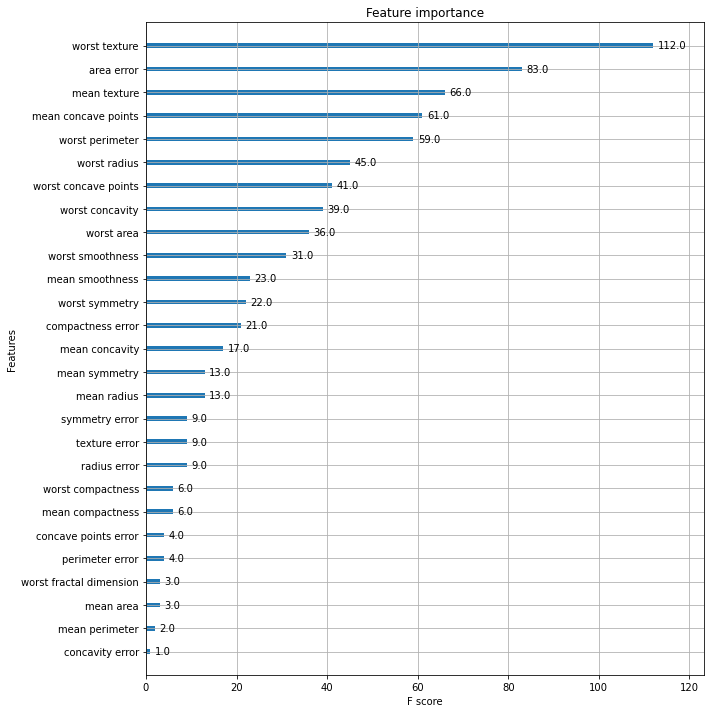
사이킷런 Wrapper XGBoost 적용
사이킷런 래퍼 클래스 임포트, 학습 및 예측
# 사이킷런 래퍼 XGBoost 클래스인 XGBClassifier 임포트
from xgboost import XGBClassifier
# Warning 메시지를 없애기 위해 eval_metric 값을 XGBClassifier 생성 인자로 입력. 미 입력해도 수행에 문제 없음.
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3, eval_metric='logloss')
xgb_wrapper.fit(X_train, y_train, verbose=True)
w_preds = xgb_wrapper.predict(X_test)
w_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]get_clf_eval(y_test , w_preds, w_pred_proba)오차 행렬
[[34 3]
[ 1 76]]
정확도: 0.9649, 정밀도: 0.9620, 재현율: 0.9870, F1: 0.9744, AUC:0.9954early stopping을 50으로 설정하고 재 학습/예측/평가
from xgboost import XGBClassifier
xgb_wrapper = XGBClassifier(n_estimators=400, learning_rate=0.05, max_depth=3)
evals = [(X_tr, y_tr), (X_val, y_val)]
xgb_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric="logloss",
eval_set=evals, verbose=True)
ws50_preds = xgb_wrapper.predict(X_test)
ws50_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1][0] validation_0-logloss:0.65016 validation_1-logloss:0.66183
[1] validation_0-logloss:0.61131 validation_1-logloss:0.63609
[2] validation_0-logloss:0.57563 validation_1-logloss:0.61144
[3] validation_0-logloss:0.54310 validation_1-logloss:0.59204
[4] validation_0-logloss:0.51323 validation_1-logloss:0.57329
[5] validation_0-logloss:0.48447 validation_1-logloss:0.55037
[6] validation_0-logloss:0.45796 validation_1-logloss:0.52929
[7] validation_0-logloss:0.43436 validation_1-logloss:0.51534
[8] validation_0-logloss:0.41150 validation_1-logloss:0.49718
[9] validation_0-logloss:0.39027 validation_1-logloss:0.48154
[10] validation_0-logloss:0.37128 validation_1-logloss:0.46990
[11] validation_0-logloss:0.35254 validation_1-logloss:0.45474
[12] validation_0-logloss:0.33528 validation_1-logloss:0.44229
[13] validation_0-logloss:0.31893 validation_1-logloss:0.42961
[14] validation_0-logloss:0.30439 validation_1-logloss:0.42065
[15] validation_0-logloss:0.29000 validation_1-logloss:0.40958
[16] validation_0-logloss:0.27651 validation_1-logloss:0.39887
[17] validation_0-logloss:0.26389 validation_1-logloss:0.39050
[18] validation_0-logloss:0.25210 validation_1-logloss:0.38254
[19] validation_0-logloss:0.24123 validation_1-logloss:0.37393
[20] validation_0-logloss:0.23076 validation_1-logloss:0.36789
[21] validation_0-logloss:0.22091 validation_1-logloss:0.36017
[22] validation_0-logloss:0.21155 validation_1-logloss:0.35421
[23] validation_0-logloss:0.20263 validation_1-logloss:0.34683
[24] validation_0-logloss:0.19434 validation_1-logloss:0.34111
[25] validation_0-logloss:0.18637 validation_1-logloss:0.33634
[26] validation_0-logloss:0.17875 validation_1-logloss:0.33082
[27] validation_0-logloss:0.17167 validation_1-logloss:0.32675
[28] validation_0-logloss:0.16481 validation_1-logloss:0.32099
[29] validation_0-logloss:0.15835 validation_1-logloss:0.31671
[30] validation_0-logloss:0.15225 validation_1-logloss:0.31277
[31] validation_0-logloss:0.14650 validation_1-logloss:0.30882
[32] validation_0-logloss:0.14102 validation_1-logloss:0.30437
[33] validation_0-logloss:0.13590 validation_1-logloss:0.30103
[34] validation_0-logloss:0.13109 validation_1-logloss:0.29794
[35] validation_0-logloss:0.12647 validation_1-logloss:0.29499
[36] validation_0-logloss:0.12197 validation_1-logloss:0.29295
[37] validation_0-logloss:0.11784 validation_1-logloss:0.29043
[38] validation_0-logloss:0.11379 validation_1-logloss:0.28927
[39] validation_0-logloss:0.10994 validation_1-logloss:0.28578
[40] validation_0-logloss:0.10638 validation_1-logloss:0.28364
[41] validation_0-logloss:0.10302 validation_1-logloss:0.28183
[42] validation_0-logloss:0.09963 validation_1-logloss:0.28005
[43] validation_0-logloss:0.09649 validation_1-logloss:0.27972
[44] validation_0-logloss:0.09359 validation_1-logloss:0.27744
[45] validation_0-logloss:0.09080 validation_1-logloss:0.27542
[46] validation_0-logloss:0.08807 validation_1-logloss:0.27504
[47] validation_0-logloss:0.08541 validation_1-logloss:0.27458
[48] validation_0-logloss:0.08299 validation_1-logloss:0.27348
[49] validation_0-logloss:0.08035 validation_1-logloss:0.27247
[50] validation_0-logloss:0.07786 validation_1-logloss:0.27163
[51] validation_0-logloss:0.07550 validation_1-logloss:0.27094
[52] validation_0-logloss:0.07344 validation_1-logloss:0.26967
[53] validation_0-logloss:0.07147 validation_1-logloss:0.27008
[54] validation_0-logloss:0.06964 validation_1-logloss:0.26890
[55] validation_0-logloss:0.06766 validation_1-logloss:0.26854
[56] validation_0-logloss:0.06592 validation_1-logloss:0.26900
[57] validation_0-logloss:0.06433 validation_1-logloss:0.26790
[58] validation_0-logloss:0.06259 validation_1-logloss:0.26663
[59] validation_0-logloss:0.06107 validation_1-logloss:0.26743
[60] validation_0-logloss:0.05957 validation_1-logloss:0.26610
[61] validation_0-logloss:0.05817 validation_1-logloss:0.26644
[62] validation_0-logloss:0.05691 validation_1-logloss:0.26673
[63] validation_0-logloss:0.05550 validation_1-logloss:0.26550
[64] validation_0-logloss:0.05422 validation_1-logloss:0.26443
[65] validation_0-logloss:0.05311 validation_1-logloss:0.26500
[66] validation_0-logloss:0.05207 validation_1-logloss:0.26591
[67] validation_0-logloss:0.05093 validation_1-logloss:0.26501
[68] validation_0-logloss:0.04976 validation_1-logloss:0.26435
[69] validation_0-logloss:0.04872 validation_1-logloss:0.26360
[70] validation_0-logloss:0.04776 validation_1-logloss:0.26319
[71] validation_0-logloss:0.04680 validation_1-logloss:0.26255
[72] validation_0-logloss:0.04580 validation_1-logloss:0.26204
[73] validation_0-logloss:0.04484 validation_1-logloss:0.26254
[74] validation_0-logloss:0.04388 validation_1-logloss:0.26289
[75] validation_0-logloss:0.04309 validation_1-logloss:0.26249
[76] validation_0-logloss:0.04224 validation_1-logloss:0.26217
[77] validation_0-logloss:0.04133 validation_1-logloss:0.26166
[78] validation_0-logloss:0.04050 validation_1-logloss:0.26179
[79] validation_0-logloss:0.03967 validation_1-logloss:0.26103
[80] validation_0-logloss:0.03877 validation_1-logloss:0.26094
[81] validation_0-logloss:0.03806 validation_1-logloss:0.26148
[82] validation_0-logloss:0.03740 validation_1-logloss:0.26054
[83] validation_0-logloss:0.03676 validation_1-logloss:0.25967
[84] validation_0-logloss:0.03605 validation_1-logloss:0.25905
[85] validation_0-logloss:0.03545 validation_1-logloss:0.26007
[86] validation_0-logloss:0.03488 validation_1-logloss:0.25984
[87] validation_0-logloss:0.03425 validation_1-logloss:0.25933
[88] validation_0-logloss:0.03361 validation_1-logloss:0.25932
[89] validation_0-logloss:0.03311 validation_1-logloss:0.26002
[90] validation_0-logloss:0.03260 validation_1-logloss:0.25936
[91] validation_0-logloss:0.03202 validation_1-logloss:0.25886
[92] validation_0-logloss:0.03152 validation_1-logloss:0.25918
[93] validation_0-logloss:0.03107 validation_1-logloss:0.25865
[94] validation_0-logloss:0.03049 validation_1-logloss:0.25951
[95] validation_0-logloss:0.03007 validation_1-logloss:0.26091
[96] validation_0-logloss:0.02963 validation_1-logloss:0.26014
[97] validation_0-logloss:0.02913 validation_1-logloss:0.25974
[98] validation_0-logloss:0.02866 validation_1-logloss:0.25937
[99] validation_0-logloss:0.02829 validation_1-logloss:0.25893
[100] validation_0-logloss:0.02789 validation_1-logloss:0.25928
[101] validation_0-logloss:0.02751 validation_1-logloss:0.25955
[102] validation_0-logloss:0.02714 validation_1-logloss:0.25901
[103] validation_0-logloss:0.02668 validation_1-logloss:0.25991
[104] validation_0-logloss:0.02634 validation_1-logloss:0.25950
[105] validation_0-logloss:0.02594 validation_1-logloss:0.25924
[106] validation_0-logloss:0.02556 validation_1-logloss:0.25901
[107] validation_0-logloss:0.02522 validation_1-logloss:0.25738
[108] validation_0-logloss:0.02492 validation_1-logloss:0.25702
[109] validation_0-logloss:0.02453 validation_1-logloss:0.25789
[110] validation_0-logloss:0.02418 validation_1-logloss:0.25770
[111] validation_0-logloss:0.02384 validation_1-logloss:0.25842
[112] validation_0-logloss:0.02356 validation_1-logloss:0.25810
[113] validation_0-logloss:0.02322 validation_1-logloss:0.25848
[114] validation_0-logloss:0.02290 validation_1-logloss:0.25833
[115] validation_0-logloss:0.02260 validation_1-logloss:0.25820
[116] validation_0-logloss:0.02229 validation_1-logloss:0.25905
[117] validation_0-logloss:0.02204 validation_1-logloss:0.25878
[118] validation_0-logloss:0.02176 validation_1-logloss:0.25728
[119] validation_0-logloss:0.02149 validation_1-logloss:0.25722
[120] validation_0-logloss:0.02119 validation_1-logloss:0.25764
[121] validation_0-logloss:0.02095 validation_1-logloss:0.25761
[122] validation_0-logloss:0.02067 validation_1-logloss:0.25832
[123] validation_0-logloss:0.02045 validation_1-logloss:0.25808
[124] validation_0-logloss:0.02023 validation_1-logloss:0.25855
[125] validation_0-logloss:0.01998 validation_1-logloss:0.25714
[126] validation_0-logloss:0.01973 validation_1-logloss:0.25587
[127] validation_0-logloss:0.01946 validation_1-logloss:0.25640
[128] validation_0-logloss:0.01927 validation_1-logloss:0.25685
[129] validation_0-logloss:0.01908 validation_1-logloss:0.25665
[130] validation_0-logloss:0.01886 validation_1-logloss:0.25712
[131] validation_0-logloss:0.01863 validation_1-logloss:0.25609
[132] validation_0-logloss:0.01839 validation_1-logloss:0.25649
[133] validation_0-logloss:0.01816 validation_1-logloss:0.25789
[134] validation_0-logloss:0.01802 validation_1-logloss:0.25811
[135] validation_0-logloss:0.01785 validation_1-logloss:0.25794
[136] validation_0-logloss:0.01763 validation_1-logloss:0.25876
[137] validation_0-logloss:0.01748 validation_1-logloss:0.25884
[138] validation_0-logloss:0.01732 validation_1-logloss:0.25867
[139] validation_0-logloss:0.01719 validation_1-logloss:0.25876
[140] validation_0-logloss:0.01696 validation_1-logloss:0.25987
[141] validation_0-logloss:0.01681 validation_1-logloss:0.25960
[142] validation_0-logloss:0.01669 validation_1-logloss:0.25982
[143] validation_0-logloss:0.01656 validation_1-logloss:0.25992
[144] validation_0-logloss:0.01638 validation_1-logloss:0.26035
[145] validation_0-logloss:0.01623 validation_1-logloss:0.26055
[146] validation_0-logloss:0.01606 validation_1-logloss:0.26092
[147] validation_0-logloss:0.01589 validation_1-logloss:0.26137
[148] validation_0-logloss:0.01572 validation_1-logloss:0.25999
[149] validation_0-logloss:0.01557 validation_1-logloss:0.26028
[150] validation_0-logloss:0.01546 validation_1-logloss:0.26048
[151] validation_0-logloss:0.01531 validation_1-logloss:0.26142
[152] validation_0-logloss:0.01515 validation_1-logloss:0.26188
[153] validation_0-logloss:0.01501 validation_1-logloss:0.26227
[154] validation_0-logloss:0.01486 validation_1-logloss:0.26287
[155] validation_0-logloss:0.01476 validation_1-logloss:0.26299
[156] validation_0-logloss:0.01461 validation_1-logloss:0.26346
[157] validation_0-logloss:0.01448 validation_1-logloss:0.26379
[158] validation_0-logloss:0.01434 validation_1-logloss:0.26306
[159] validation_0-logloss:0.01424 validation_1-logloss:0.26237
[160] validation_0-logloss:0.01410 validation_1-logloss:0.26251
[161] validation_0-logloss:0.01401 validation_1-logloss:0.26265
[162] validation_0-logloss:0.01392 validation_1-logloss:0.26264
[163] validation_0-logloss:0.01380 validation_1-logloss:0.26250
[164] validation_0-logloss:0.01372 validation_1-logloss:0.26264
[165] validation_0-logloss:0.01359 validation_1-logloss:0.26255
[166] validation_0-logloss:0.01350 validation_1-logloss:0.26188
[167] validation_0-logloss:0.01342 validation_1-logloss:0.26203
[168] validation_0-logloss:0.01331 validation_1-logloss:0.26190
[169] validation_0-logloss:0.01319 validation_1-logloss:0.26184
[170] validation_0-logloss:0.01312 validation_1-logloss:0.26133
[171] validation_0-logloss:0.01304 validation_1-logloss:0.26148
[172] validation_0-logloss:0.01297 validation_1-logloss:0.26157
[173] validation_0-logloss:0.01285 validation_1-logloss:0.26253
[174] validation_0-logloss:0.01278 validation_1-logloss:0.26229
[175] validation_0-logloss:0.01267 validation_1-logloss:0.26086get_clf_eval(y_test , ws50_preds, ws50_pred_proba)오차 행렬
[[34 3]
[ 2 75]]
정확도: 0.9561, 정밀도: 0.9615, 재현율: 0.9740, F1: 0.9677, AUC:0.9933early stopping을 10으로 설정하고 재 학습/예측/평가
# early_stopping_rounds를 10으로 설정하고 재 학습.
xgb_wrapper.fit(X_tr, y_tr, early_stopping_rounds=10,
eval_metric="logloss", eval_set=evals,verbose=True)
ws10_preds = xgb_wrapper.predict(X_test)
ws10_pred_proba = xgb_wrapper.predict_proba(X_test)[:, 1]
get_clf_eval(y_test , ws10_preds, ws10_pred_proba)[0] validation_0-logloss:0.65016 validation_1-logloss:0.66183
[1] validation_0-logloss:0.61131 validation_1-logloss:0.63609
[2] validation_0-logloss:0.57563 validation_1-logloss:0.61144
[3] validation_0-logloss:0.54310 validation_1-logloss:0.59204
[4] validation_0-logloss:0.51323 validation_1-logloss:0.57329
[5] validation_0-logloss:0.48447 validation_1-logloss:0.55037
[6] validation_0-logloss:0.45796 validation_1-logloss:0.52929
[7] validation_0-logloss:0.43436 validation_1-logloss:0.51534
[8] validation_0-logloss:0.41150 validation_1-logloss:0.49718
[9] validation_0-logloss:0.39027 validation_1-logloss:0.48154
[10] validation_0-logloss:0.37128 validation_1-logloss:0.46990
[11] validation_0-logloss:0.35254 validation_1-logloss:0.45474
[12] validation_0-logloss:0.33528 validation_1-logloss:0.44229
[13] validation_0-logloss:0.31893 validation_1-logloss:0.42961
[14] validation_0-logloss:0.30439 validation_1-logloss:0.42065
[15] validation_0-logloss:0.29000 validation_1-logloss:0.40958
[16] validation_0-logloss:0.27651 validation_1-logloss:0.39887
[17] validation_0-logloss:0.26389 validation_1-logloss:0.39050
[18] validation_0-logloss:0.25210 validation_1-logloss:0.38254
[19] validation_0-logloss:0.24123 validation_1-logloss:0.37393
[20] validation_0-logloss:0.23076 validation_1-logloss:0.36789
[21] validation_0-logloss:0.22091 validation_1-logloss:0.36017
[22] validation_0-logloss:0.21155 validation_1-logloss:0.35421
[23] validation_0-logloss:0.20263 validation_1-logloss:0.34683
[24] validation_0-logloss:0.19434 validation_1-logloss:0.34111
[25] validation_0-logloss:0.18637 validation_1-logloss:0.33634
[26] validation_0-logloss:0.17875 validation_1-logloss:0.33082
[27] validation_0-logloss:0.17167 validation_1-logloss:0.32675
[28] validation_0-logloss:0.16481 validation_1-logloss:0.32099
[29] validation_0-logloss:0.15835 validation_1-logloss:0.31671
[30] validation_0-logloss:0.15225 validation_1-logloss:0.31277
[31] validation_0-logloss:0.14650 validation_1-logloss:0.30882
[32] validation_0-logloss:0.14102 validation_1-logloss:0.30437
[33] validation_0-logloss:0.13590 validation_1-logloss:0.30103
[34] validation_0-logloss:0.13109 validation_1-logloss:0.29794
[35] validation_0-logloss:0.12647 validation_1-logloss:0.29499
[36] validation_0-logloss:0.12197 validation_1-logloss:0.29295
[37] validation_0-logloss:0.11784 validation_1-logloss:0.29043
[38] validation_0-logloss:0.11379 validation_1-logloss:0.28927
[39] validation_0-logloss:0.10994 validation_1-logloss:0.28578
[40] validation_0-logloss:0.10638 validation_1-logloss:0.28364
[41] validation_0-logloss:0.10302 validation_1-logloss:0.28183
[42] validation_0-logloss:0.09963 validation_1-logloss:0.28005
[43] validation_0-logloss:0.09649 validation_1-logloss:0.27972
[44] validation_0-logloss:0.09359 validation_1-logloss:0.27744
[45] validation_0-logloss:0.09080 validation_1-logloss:0.27542
[46] validation_0-logloss:0.08807 validation_1-logloss:0.27504
[47] validation_0-logloss:0.08541 validation_1-logloss:0.27458
[48] validation_0-logloss:0.08299 validation_1-logloss:0.27348
[49] validation_0-logloss:0.08035 validation_1-logloss:0.27247
[50] validation_0-logloss:0.07786 validation_1-logloss:0.27163
[51] validation_0-logloss:0.07550 validation_1-logloss:0.27094
[52] validation_0-logloss:0.07344 validation_1-logloss:0.26967
[53] validation_0-logloss:0.07147 validation_1-logloss:0.27008
[54] validation_0-logloss:0.06964 validation_1-logloss:0.26890
[55] validation_0-logloss:0.06766 validation_1-logloss:0.26854
[56] validation_0-logloss:0.06592 validation_1-logloss:0.26900
[57] validation_0-logloss:0.06433 validation_1-logloss:0.26790
[58] validation_0-logloss:0.06259 validation_1-logloss:0.26663
[59] validation_0-logloss:0.06107 validation_1-logloss:0.26743
[60] validation_0-logloss:0.05957 validation_1-logloss:0.26610
[61] validation_0-logloss:0.05817 validation_1-logloss:0.26644
[62] validation_0-logloss:0.05691 validation_1-logloss:0.26673
[63] validation_0-logloss:0.05550 validation_1-logloss:0.26550
[64] validation_0-logloss:0.05422 validation_1-logloss:0.26443
[65] validation_0-logloss:0.05311 validation_1-logloss:0.26500
[66] validation_0-logloss:0.05207 validation_1-logloss:0.26591
[67] validation_0-logloss:0.05093 validation_1-logloss:0.26501
[68] validation_0-logloss:0.04976 validation_1-logloss:0.26435
[69] validation_0-logloss:0.04872 validation_1-logloss:0.26360
[70] validation_0-logloss:0.04776 validation_1-logloss:0.26319
[71] validation_0-logloss:0.04680 validation_1-logloss:0.26255
[72] validation_0-logloss:0.04580 validation_1-logloss:0.26204
[73] validation_0-logloss:0.04484 validation_1-logloss:0.26254
[74] validation_0-logloss:0.04388 validation_1-logloss:0.26289
[75] validation_0-logloss:0.04309 validation_1-logloss:0.26249
[76] validation_0-logloss:0.04224 validation_1-logloss:0.26217
[77] validation_0-logloss:0.04133 validation_1-logloss:0.26166
[78] validation_0-logloss:0.04050 validation_1-logloss:0.26179
[79] validation_0-logloss:0.03967 validation_1-logloss:0.26103
[80] validation_0-logloss:0.03877 validation_1-logloss:0.26094
[81] validation_0-logloss:0.03806 validation_1-logloss:0.26148
[82] validation_0-logloss:0.03740 validation_1-logloss:0.26054
[83] validation_0-logloss:0.03676 validation_1-logloss:0.25967
[84] validation_0-logloss:0.03605 validation_1-logloss:0.25905
[85] validation_0-logloss:0.03545 validation_1-logloss:0.26007
[86] validation_0-logloss:0.03488 validation_1-logloss:0.25984
[87] validation_0-logloss:0.03425 validation_1-logloss:0.25933
[88] validation_0-logloss:0.03361 validation_1-logloss:0.25932
[89] validation_0-logloss:0.03311 validation_1-logloss:0.26002
[90] validation_0-logloss:0.03260 validation_1-logloss:0.25936
[91] validation_0-logloss:0.03202 validation_1-logloss:0.25886
[92] validation_0-logloss:0.03152 validation_1-logloss:0.25918
[93] validation_0-logloss:0.03107 validation_1-logloss:0.25865
[94] validation_0-logloss:0.03049 validation_1-logloss:0.25951
[95] validation_0-logloss:0.03007 validation_1-logloss:0.26091
[96] validation_0-logloss:0.02963 validation_1-logloss:0.26014
[97] validation_0-logloss:0.02913 validation_1-logloss:0.25974
[98] validation_0-logloss:0.02866 validation_1-logloss:0.25937
[99] validation_0-logloss:0.02829 validation_1-logloss:0.25893
[100] validation_0-logloss:0.02789 validation_1-logloss:0.25928
[101] validation_0-logloss:0.02751 validation_1-logloss:0.25955
[102] validation_0-logloss:0.02714 validation_1-logloss:0.25901
오차 행렬
[[34 3]
[ 3 74]]
정확도: 0.9474, 정밀도: 0.9610, 재현율: 0.9610, F1: 0.9610, AUC:0.9933from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
# 사이킷런 래퍼 클래스를 입력해도 무방.
plot_importance(xgb_wrapper, ax=ax)<AxesSubplot:title={'center':'Feature importance'}, xlabel='F score', ylabel='Features'>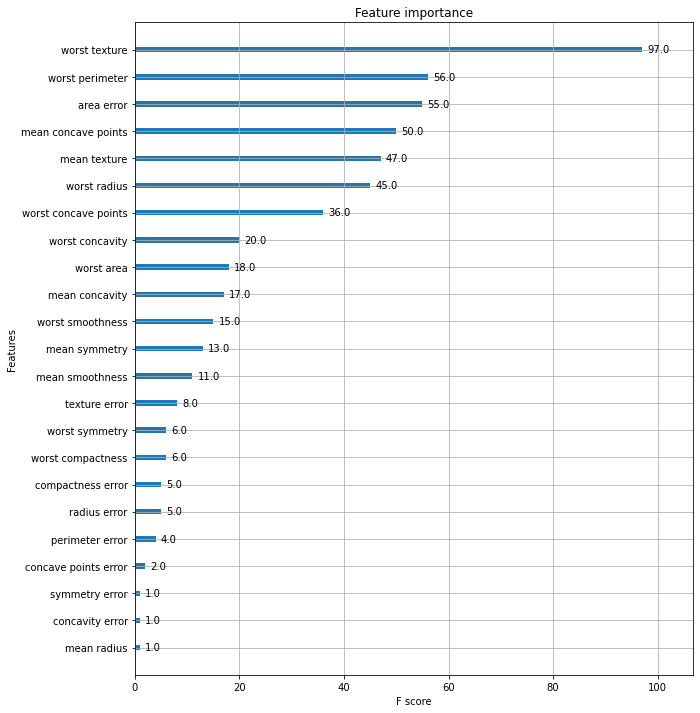
LightGBM
XGBoost 대비 장점
- 더 빠른 학습과 예측 수행 시간
- (XGBoost같은 경우 데이터가 클 경우 학습 시간이 이상적으로 길어질 수 있으며, 튜닝이 어려워진다.)
- 더 작은 메모리 사용량
- 카테고리형 피처의 자동 변환과 최적 분활(원-핫 인코딩 등을 사용하지 않고도 카테고리형 피처를 최적으로 변환하고 이에 따른 노드 분활 수행)
트리 분활 방식
- 균형 트리 분활(Level Wise)
일반적으로 GBM계열들은 depth를 최적화하기 위해서 트리를 균형잡힌 트리로 형성한다.
이는 과적합을 이룰 수 있는 확률이 높음 - 리프 중심 트리 분활(Leaf Wise)
예측 오류를 줄여줄 수 있는 뱡향성이 있는 리프노드를 기준으로 계속해서 리프노드를 생성하며 분활해간다
->LightGBM
LightGBM 적용 – 위스콘신 Breast Cancer Prediction
# LightGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier 임포트
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')
dataset = load_breast_cancer()
cancer_df = pd.DataFrame(data=dataset.data, columns=dataset.feature_names)
cancer_df['target']= dataset.target
cancer_df.head()| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
5 rows × 31 columns
X_features = cancer_df.iloc[:, :-1]
y_label = cancer_df.iloc[:, -1]
# 전체 데이터 중 80%는 학습용 데이터, 20%는 테스트용 데이터 추출
X_train, X_test, y_train, y_test=train_test_split(X_features, y_label,
test_size=0.2, random_state=156 )
# 위에서 만든 X_train, y_train을 다시 쪼개서 90%는 학습과 10%는 검증용 데이터로 분리
X_tr, X_val, y_tr, y_val= train_test_split(X_train, y_train,
test_size=0.1, random_state=156 )
# 앞서 XGBoost와 동일하게 n_estimators는 400 설정.
lgbm_wrapper = LGBMClassifier(n_estimators=400, learning_rate=0.05)
# LightGBM도 XGBoost와 동일하게 조기 중단 수행 가능.
evals = [(X_tr, y_tr), (X_val, y_val)]
lgbm_wrapper.fit(X_tr, y_tr, early_stopping_rounds=50, eval_metric="logloss",
eval_set=evals, verbose=True)
preds = lgbm_wrapper.predict(X_test)
pred_proba = lgbm_wrapper.predict_proba(X_test)[:, 1][1] training's binary_logloss: 0.625671 valid_1's binary_logloss: 0.628248
[2] training's binary_logloss: 0.588173 valid_1's binary_logloss: 0.601106
[3] training's binary_logloss: 0.554518 valid_1's binary_logloss: 0.577587
[4] training's binary_logloss: 0.523972 valid_1's binary_logloss: 0.556324
[5] training's binary_logloss: 0.49615 valid_1's binary_logloss: 0.537407
[6] training's binary_logloss: 0.470108 valid_1's binary_logloss: 0.519401
[7] training's binary_logloss: 0.446647 valid_1's binary_logloss: 0.502637
[8] training's binary_logloss: 0.425055 valid_1's binary_logloss: 0.488311
[9] training's binary_logloss: 0.405125 valid_1's binary_logloss: 0.474664
[10] training's binary_logloss: 0.386526 valid_1's binary_logloss: 0.461267
[11] training's binary_logloss: 0.367027 valid_1's binary_logloss: 0.444274
[12] training's binary_logloss: 0.350713 valid_1's binary_logloss: 0.432755
[13] training's binary_logloss: 0.334601 valid_1's binary_logloss: 0.421371
[14] training's binary_logloss: 0.319854 valid_1's binary_logloss: 0.411418
[15] training's binary_logloss: 0.306374 valid_1's binary_logloss: 0.402989
[16] training's binary_logloss: 0.293116 valid_1's binary_logloss: 0.393973
[17] training's binary_logloss: 0.280812 valid_1's binary_logloss: 0.384801
[18] training's binary_logloss: 0.268352 valid_1's binary_logloss: 0.376191
[19] training's binary_logloss: 0.256942 valid_1's binary_logloss: 0.368378
[20] training's binary_logloss: 0.246443 valid_1's binary_logloss: 0.362062
[21] training's binary_logloss: 0.236874 valid_1's binary_logloss: 0.355162
[22] training's binary_logloss: 0.227501 valid_1's binary_logloss: 0.348933
[23] training's binary_logloss: 0.218988 valid_1's binary_logloss: 0.342819
[24] training's binary_logloss: 0.210621 valid_1's binary_logloss: 0.337386
[25] training's binary_logloss: 0.202076 valid_1's binary_logloss: 0.331523
[26] training's binary_logloss: 0.194199 valid_1's binary_logloss: 0.326349
[27] training's binary_logloss: 0.187107 valid_1's binary_logloss: 0.322785
[28] training's binary_logloss: 0.180535 valid_1's binary_logloss: 0.317877
[29] training's binary_logloss: 0.173834 valid_1's binary_logloss: 0.313928
[30] training's binary_logloss: 0.167198 valid_1's binary_logloss: 0.310105
[31] training's binary_logloss: 0.161229 valid_1's binary_logloss: 0.307107
[32] training's binary_logloss: 0.155494 valid_1's binary_logloss: 0.303837
[33] training's binary_logloss: 0.149125 valid_1's binary_logloss: 0.300315
[34] training's binary_logloss: 0.144045 valid_1's binary_logloss: 0.297816
[35] training's binary_logloss: 0.139341 valid_1's binary_logloss: 0.295387
[36] training's binary_logloss: 0.134625 valid_1's binary_logloss: 0.293063
[37] training's binary_logloss: 0.129167 valid_1's binary_logloss: 0.289127
[38] training's binary_logloss: 0.12472 valid_1's binary_logloss: 0.288697
[39] training's binary_logloss: 0.11974 valid_1's binary_logloss: 0.28576
[40] training's binary_logloss: 0.115054 valid_1's binary_logloss: 0.282853
[41] training's binary_logloss: 0.110662 valid_1's binary_logloss: 0.279441
[42] training's binary_logloss: 0.106358 valid_1's binary_logloss: 0.28113
[43] training's binary_logloss: 0.102324 valid_1's binary_logloss: 0.279139
[44] training's binary_logloss: 0.0985699 valid_1's binary_logloss: 0.276465
[45] training's binary_logloss: 0.094858 valid_1's binary_logloss: 0.275946
[46] training's binary_logloss: 0.0912486 valid_1's binary_logloss: 0.272819
[47] training's binary_logloss: 0.0883115 valid_1's binary_logloss: 0.272306
[48] training's binary_logloss: 0.0849963 valid_1's binary_logloss: 0.270452
[49] training's binary_logloss: 0.0821742 valid_1's binary_logloss: 0.268671
[50] training's binary_logloss: 0.0789991 valid_1's binary_logloss: 0.267587
[51] training's binary_logloss: 0.0761072 valid_1's binary_logloss: 0.26626
[52] training's binary_logloss: 0.0732567 valid_1's binary_logloss: 0.265542
[53] training's binary_logloss: 0.0706388 valid_1's binary_logloss: 0.264547
[54] training's binary_logloss: 0.0683911 valid_1's binary_logloss: 0.26502
[55] training's binary_logloss: 0.0659347 valid_1's binary_logloss: 0.264388
[56] training's binary_logloss: 0.0636873 valid_1's binary_logloss: 0.263128
[57] training's binary_logloss: 0.0613354 valid_1's binary_logloss: 0.26231
[58] training's binary_logloss: 0.0591944 valid_1's binary_logloss: 0.262011
[59] training's binary_logloss: 0.057033 valid_1's binary_logloss: 0.261454
[60] training's binary_logloss: 0.0550801 valid_1's binary_logloss: 0.260746
[61] training's binary_logloss: 0.0532381 valid_1's binary_logloss: 0.260236
[62] training's binary_logloss: 0.0514074 valid_1's binary_logloss: 0.261586
[63] training's binary_logloss: 0.0494837 valid_1's binary_logloss: 0.261797
[64] training's binary_logloss: 0.0477826 valid_1's binary_logloss: 0.262533
[65] training's binary_logloss: 0.0460364 valid_1's binary_logloss: 0.263305
[66] training's binary_logloss: 0.0444552 valid_1's binary_logloss: 0.264072
[67] training's binary_logloss: 0.0427638 valid_1's binary_logloss: 0.266223
[68] training's binary_logloss: 0.0412449 valid_1's binary_logloss: 0.266817
[69] training's binary_logloss: 0.0398589 valid_1's binary_logloss: 0.267819
[70] training's binary_logloss: 0.0383095 valid_1's binary_logloss: 0.267484
[71] training's binary_logloss: 0.0368803 valid_1's binary_logloss: 0.270233
[72] training's binary_logloss: 0.0355637 valid_1's binary_logloss: 0.268442
[73] training's binary_logloss: 0.0341747 valid_1's binary_logloss: 0.26895
[74] training's binary_logloss: 0.0328302 valid_1's binary_logloss: 0.266958
[75] training's binary_logloss: 0.0317853 valid_1's binary_logloss: 0.268091
[76] training's binary_logloss: 0.0305626 valid_1's binary_logloss: 0.266419
[77] training's binary_logloss: 0.0295001 valid_1's binary_logloss: 0.268588
[78] training's binary_logloss: 0.0284699 valid_1's binary_logloss: 0.270964
[79] training's binary_logloss: 0.0273953 valid_1's binary_logloss: 0.270293
[80] training's binary_logloss: 0.0264668 valid_1's binary_logloss: 0.270523
[81] training's binary_logloss: 0.0254636 valid_1's binary_logloss: 0.270683
[82] training's binary_logloss: 0.0245911 valid_1's binary_logloss: 0.273187
[83] training's binary_logloss: 0.0236486 valid_1's binary_logloss: 0.275994
[84] training's binary_logloss: 0.0228047 valid_1's binary_logloss: 0.274053
[85] training's binary_logloss: 0.0221693 valid_1's binary_logloss: 0.273211
[86] training's binary_logloss: 0.0213043 valid_1's binary_logloss: 0.272626
[87] training's binary_logloss: 0.0203934 valid_1's binary_logloss: 0.27534
[88] training's binary_logloss: 0.0195552 valid_1's binary_logloss: 0.276228
[89] training's binary_logloss: 0.0188623 valid_1's binary_logloss: 0.27525
[90] training's binary_logloss: 0.0183664 valid_1's binary_logloss: 0.276485
[91] training's binary_logloss: 0.0176788 valid_1's binary_logloss: 0.277052
[92] training's binary_logloss: 0.0170059 valid_1's binary_logloss: 0.277686
[93] training's binary_logloss: 0.0164317 valid_1's binary_logloss: 0.275332
[94] training's binary_logloss: 0.015878 valid_1's binary_logloss: 0.276236
[95] training's binary_logloss: 0.0152959 valid_1's binary_logloss: 0.274538
[96] training's binary_logloss: 0.0147216 valid_1's binary_logloss: 0.275244
[97] training's binary_logloss: 0.0141758 valid_1's binary_logloss: 0.275829
[98] training's binary_logloss: 0.0136551 valid_1's binary_logloss: 0.276654
[99] training's binary_logloss: 0.0131585 valid_1's binary_logloss: 0.277859
[100] training's binary_logloss: 0.0126961 valid_1's binary_logloss: 0.279265
[101] training's binary_logloss: 0.0122421 valid_1's binary_logloss: 0.276695
[102] training's binary_logloss: 0.0118067 valid_1's binary_logloss: 0.278488
[103] training's binary_logloss: 0.0113994 valid_1's binary_logloss: 0.278932
[104] training's binary_logloss: 0.0109799 valid_1's binary_logloss: 0.280997
[105] training's binary_logloss: 0.0105953 valid_1's binary_logloss: 0.281454
[106] training's binary_logloss: 0.0102381 valid_1's binary_logloss: 0.282058
[107] training's binary_logloss: 0.00986714 valid_1's binary_logloss: 0.279275
[108] training's binary_logloss: 0.00950998 valid_1's binary_logloss: 0.281427
[109] training's binary_logloss: 0.00915965 valid_1's binary_logloss: 0.280752
[110] training's binary_logloss: 0.00882581 valid_1's binary_logloss: 0.282152
[111] training's binary_logloss: 0.00850714 valid_1's binary_logloss: 0.280894from sklearn.metrics import confusion_matrix, accuracy_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import f1_score, roc_auc_score
def get_clf_eval(y_test, pred=None, pred_proba=None):
confusion = confusion_matrix( y_test, pred)
accuracy = accuracy_score(y_test , pred)
precision = precision_score(y_test , pred)
recall = recall_score(y_test , pred)
f1 = f1_score(y_test,pred)
# ROC-AUC 추가
roc_auc = roc_auc_score(y_test, pred_proba)
print('오차 행렬')
print(confusion)
# ROC-AUC print 추가
print('정확도: {0:.4f}, 정밀도: {1:.4f}, 재현율: {2:.4f},\
F1: {3:.4f}, AUC:{4:.4f}'.format(accuracy, precision, recall, f1, roc_auc))get_clf_eval(y_test, preds, pred_proba)오차 행렬
[[34 3]
[ 2 75]]
정확도: 0.9561, 정밀도: 0.9615, 재현율: 0.9740, F1: 0.9677, AUC:0.9877# plot_importance( )를 이용하여 feature 중요도 시각화
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 12))
plot_importance(lgbm_wrapper, ax=ax)
plt.show()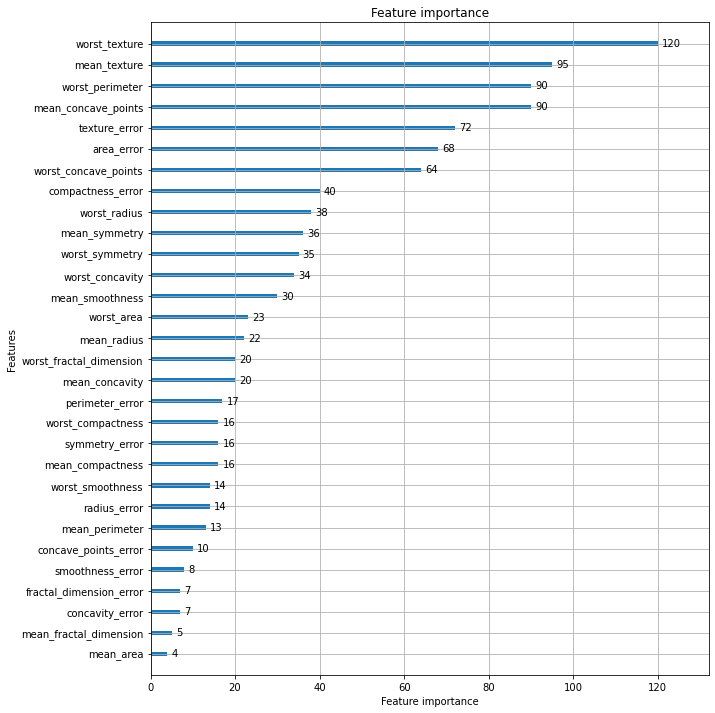
[참고] 혼자공부하는 머신러닝 + 딥러닝 / 파이썬 머신러닝 완벽 가이드